"CNN"을 들어가기전 지난 수업 내용 Neural Networks을 잠깐 되돌아 보자.
 |
Linear Score의 경우:오직 Matrix 연산만 하게 되므로, 아래와 같이 단순한 문제밖에 못 풀게 됨. (즉, 성능이 매우 나쁘다. 정확도 매우 낮음)
| Linear Score 의 문제점 | |
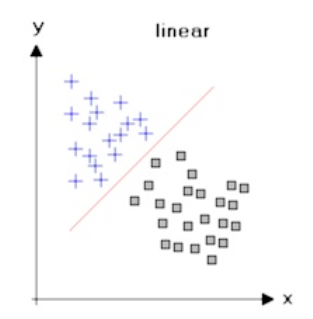 |
 |
nonlinear layer(: hidden layer)의 등장 (e.g softmax)
 |
Linear Score : W1x → Non-linear Score : W2max(0, W1x)
hidden layer(softmax function)를 추가 하면 신경망으로 바꿀 수 있는데, 이는 문제점을 해결하는데 도움이 될 수 있었음을 확인했었다.
이제 Convolutional Neural Networks 를 확인할 차례
 |
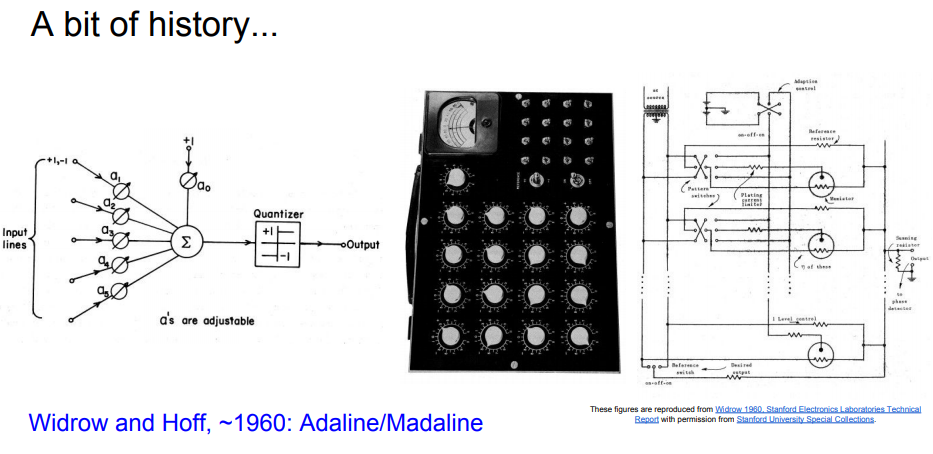
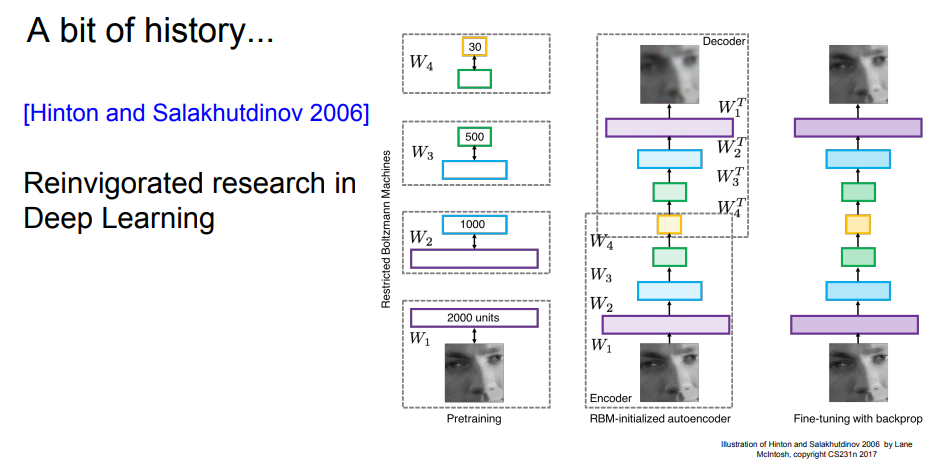
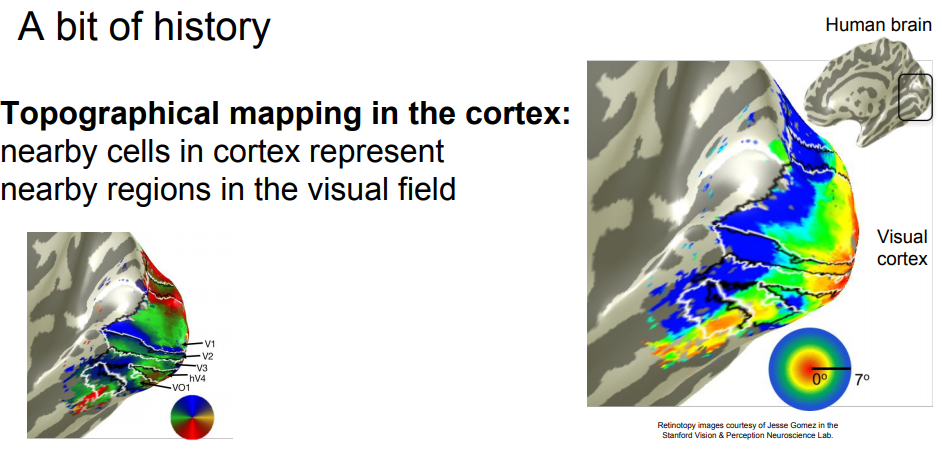
잠깐 Convolutional Neural Networks 전에 History를 확인해보자.
A bit of History (CNN)
CNN에에 대한 역사를 길게 살펴보고 있다. backpropagation,
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
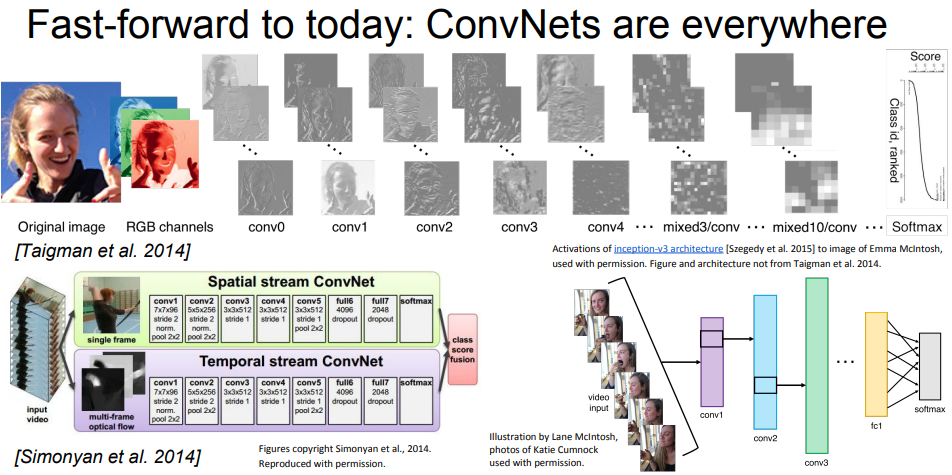
Fast-forward to today : ConvNets are everywhere
 |
 |
 |
 |
 |
 |
 |
 |
 |
다양한 분야에서 활용되는 CNN! |
Convolutional Neural Networks (First without the brain stuff)
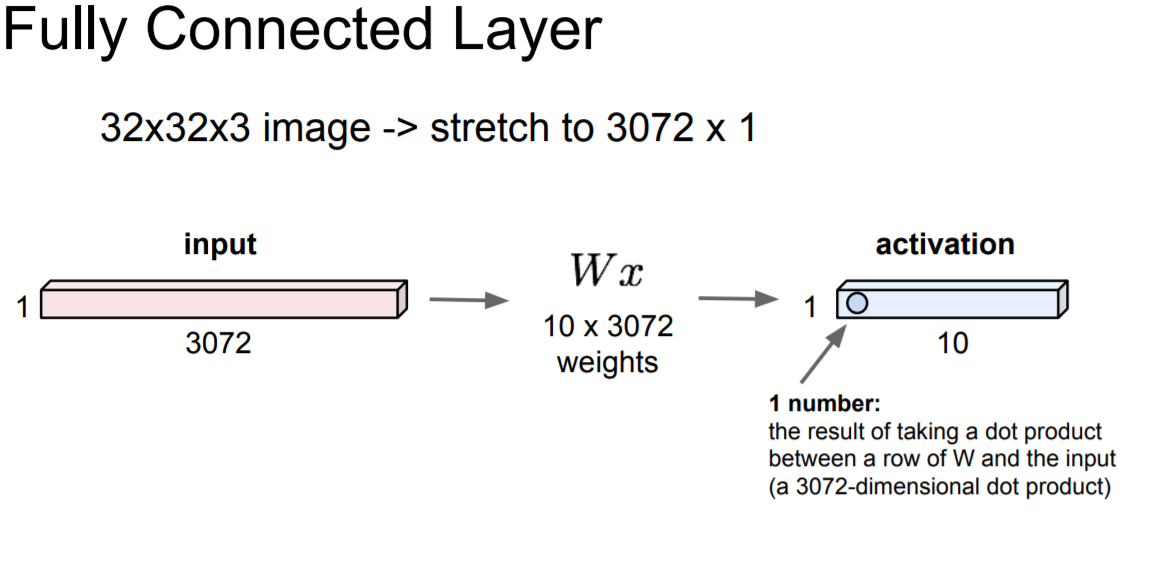 |
Fully Connected Layer는 32x32x3(Width, Height, RGB)의 정보를 가진 input를 row vector(3072)로 stretch시켜 가중치(10x3072) 계산(dot product) 및 활성화 함수를 걸쳐 나오는 값은 크기 10(각각 뉴런의 가치)을 가지게 된다. 기존 FC 방법은 여기서 문제점이 발생하는데, 정보를 직렬화하기 때문에 공간 구조(정보)를 잃게 된다.
여기서부터 image의 spatial structure를 보존(preserve)하기 위해 Convolution Layer를 도입하게 된다.
 |
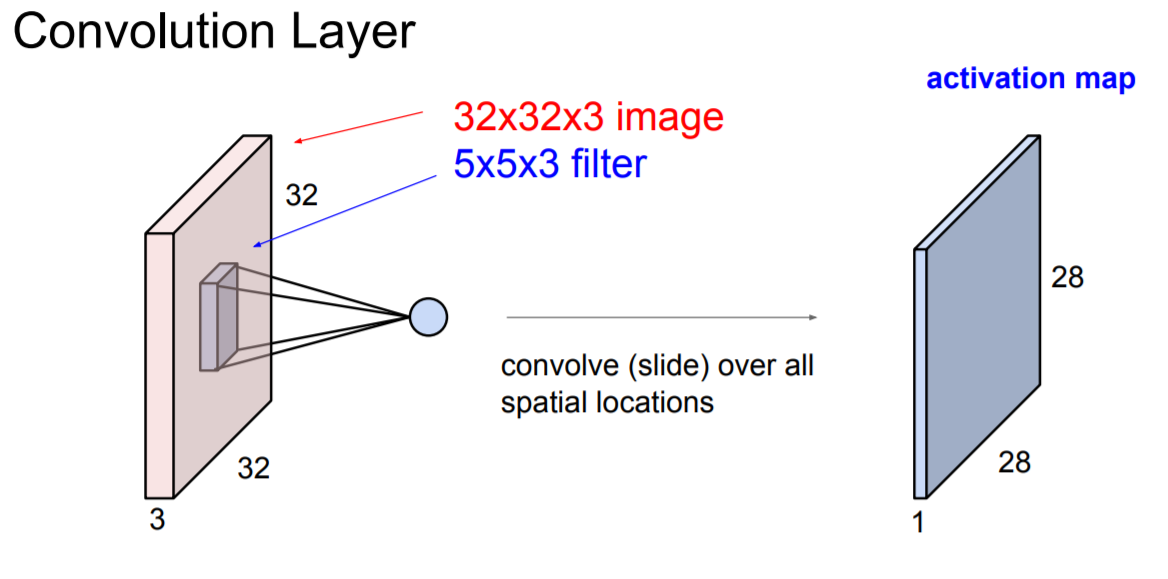
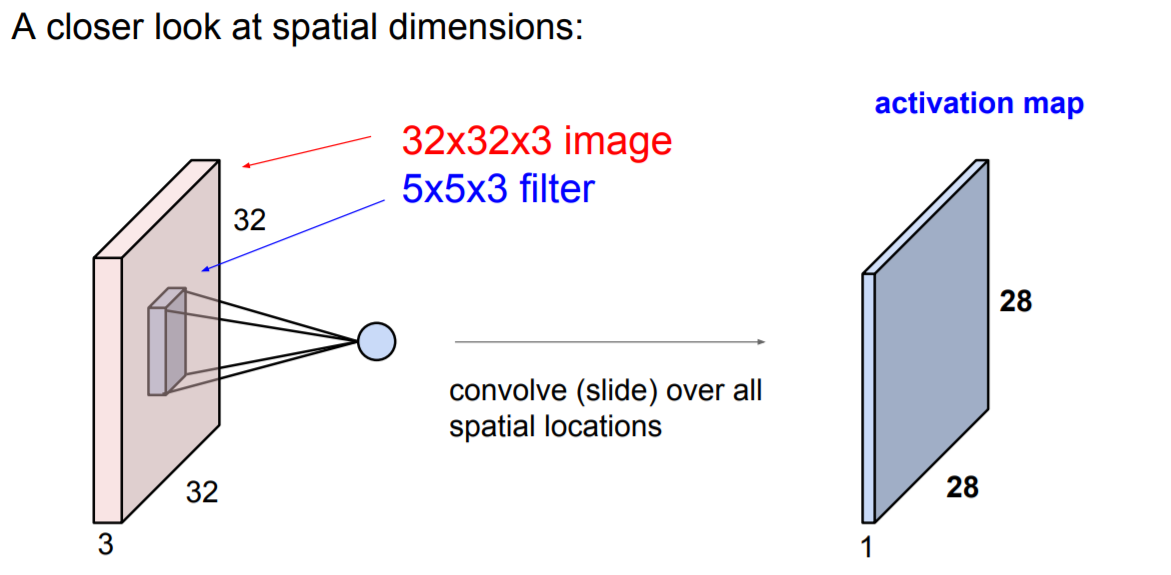
32 x 32 x 3 (width, heigh, depth)를 가지는 input이 있다고 하자. depth는 RGB(color)로 가정
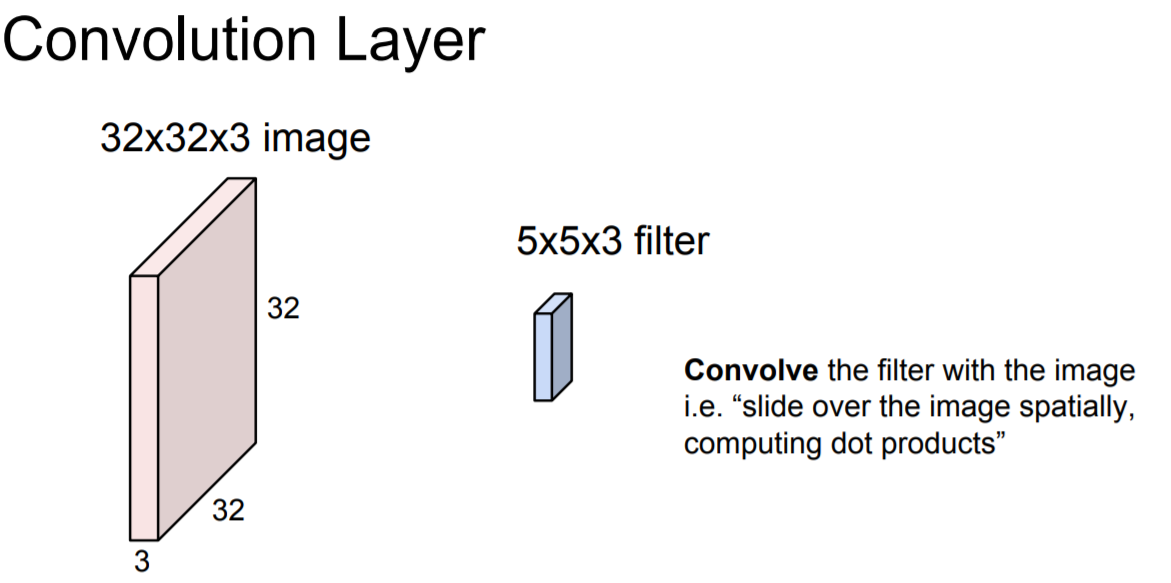 |
5 x 5 x 3 filter 를 image(32 x 32 x 5)와 연결해보자. (즉, 이미지를 공간적으로 슬라이드하면서 내적 계산).
 |
Filter의 depth는 항상 input volume의 depth와 같아야 한다. (이유 : 내적을 통해 output을 1 number로 표현해야함, 아래 참고)
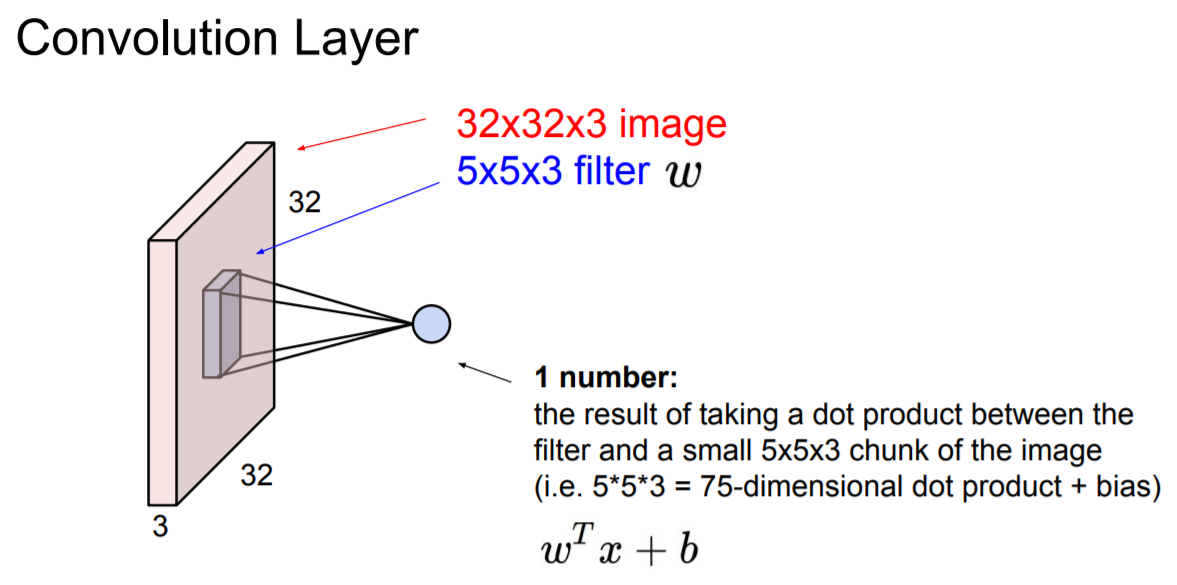 |
Filter를 가지고 input의 한 지점에 대해 계산(내적)을 할 수 있다.
- w (matrix) : Filter (Weight)
- x (matrix) : input의 한 지점
- b (scalar) : bias
위의 값들을 계산하면 하나의 값(1 number, scalar)이 나오게 된다. 그리고 input의 모든 영역에 대해 위 과정을 슬라이드(반복)하면 아래과 같이 activation map(28 x 28 x 1)이 형성된다.
 |
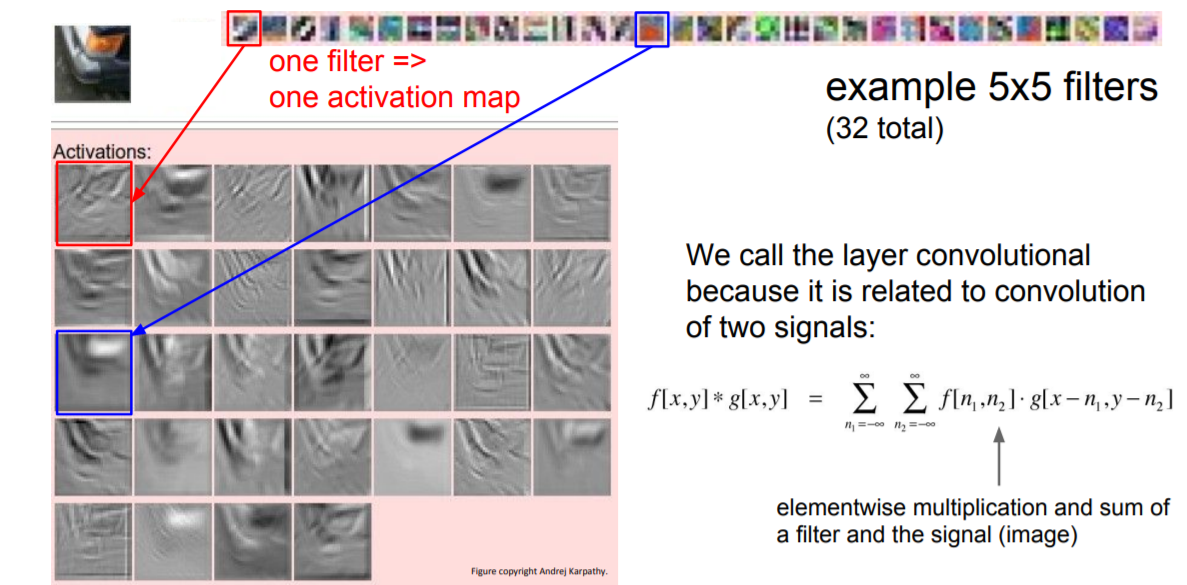
5x5x3인 하나의 Filter(파랑색)로 input의 모든 지역을 convolve하고, 추가적으로 다른 Filter(녹색)로 위의 값들을 계산하면 다음과 같이 activation maps이 아래처럼 형성된다.
 |
만약, 5 x 5 filter 6개를 가지고 있다면, 다음과 같이 activation maps(28 x 28 x 6)이 형성된다. (즉, 28 x 28 x 6이라는 새로운 image를 얻게 된다.)
 |
이처럼 순차적으로 Filter를 다양(activation function도 하나의 filter 종류)하게 주면 depth가 늘어나는것을 확인할 수 있다. (3 -> 6 -> 10 ...) 이미지의 특징을 추출해나가는 과정임!
 |
위 처럼 Filter를 통해 image의 특징을 추출하여 시각화하면 다음과 같다고 한다.
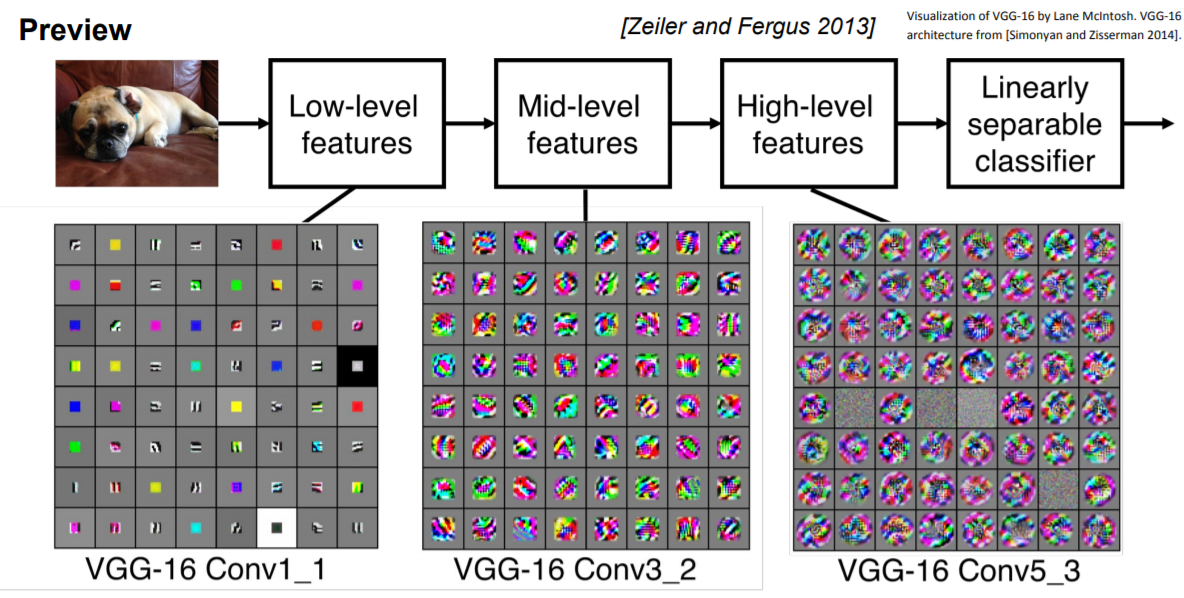 |
VGG(model)에서 학습된 activation map을 Low-Level(입력에서 첫번째 Filter 적용, 색상, 모서리)에서 High-Level로 갈수록 더 자세한 영역까지 다룰 수 있는 것을 볼 수 있다.
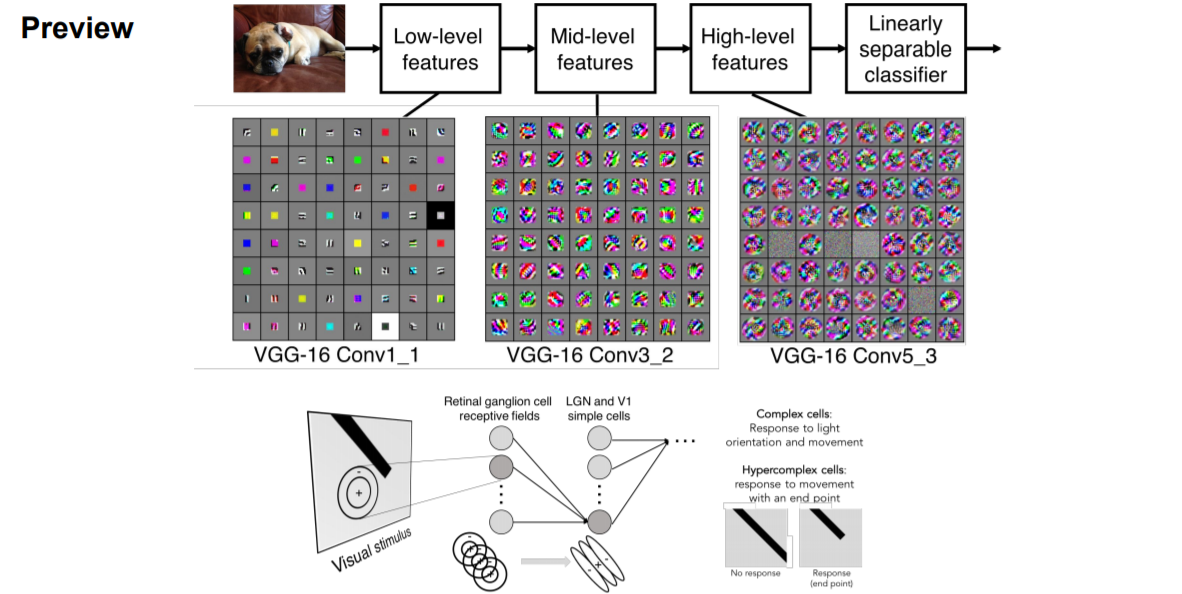 |
위의 현상은 과거에 이미 다른 연구로부터 얻은 이론과 같은 의미이다. (뉴런의 활성화를 극대화)
 |
하나의 Filter를 sequence별로 시각화했을 때 자세히 살펴보면, 원본 이미지의 주황색 부분이 다소 밝게 칠해진 것을 볼 수 있다. 즉, filter에 따른 activation map이 다르게 나와 각 filter들이 특징을 추출해내는 것을 볼 수 있다.
 |
위는 자동차 image를 filter에 의해 계산을 하면서 activation map을 시각화해서 보여주며, 마지막 과정에서는 FC를 통해 label까지 출력하는 과정을 나타내고 있다. 하지만, 더 자세히보면, RELU 및 POOL(sampling, resizing)이 있는 Layer에서는 CONV와 달리 activation map이 다소 어두운 것을 보여주고 있는데, 그 이유는 뭘까?

ReLU 그래프를 살펴보면 filter를 통해 계산된 값이 만약, 0이하의 값이라면 해당 값을 0으로 만들어 버린다. 즉, 0아래의 값들은 전부 0으로 설정되기 때문에, 모두 검정색이 되는 것이다. 이어서 pooling layer는 앞서 ReLU에 의해 결과의 샘플 및 resize이기 때문에 검정색으로 표현되고 있다. (위 그림에서 RGB depth를 모두 표현한게 아니라 하나의 depth만 가져와 시각화했기 때문에 흰/검정인 그레이색으로 나오는 것이다.)
이제 본격적으로 image의 spatial structure를 보존(preserve)하기 위해 Convolution Layer를 계산하는 방법에 대해 알아보자. (작동 원리)
 |
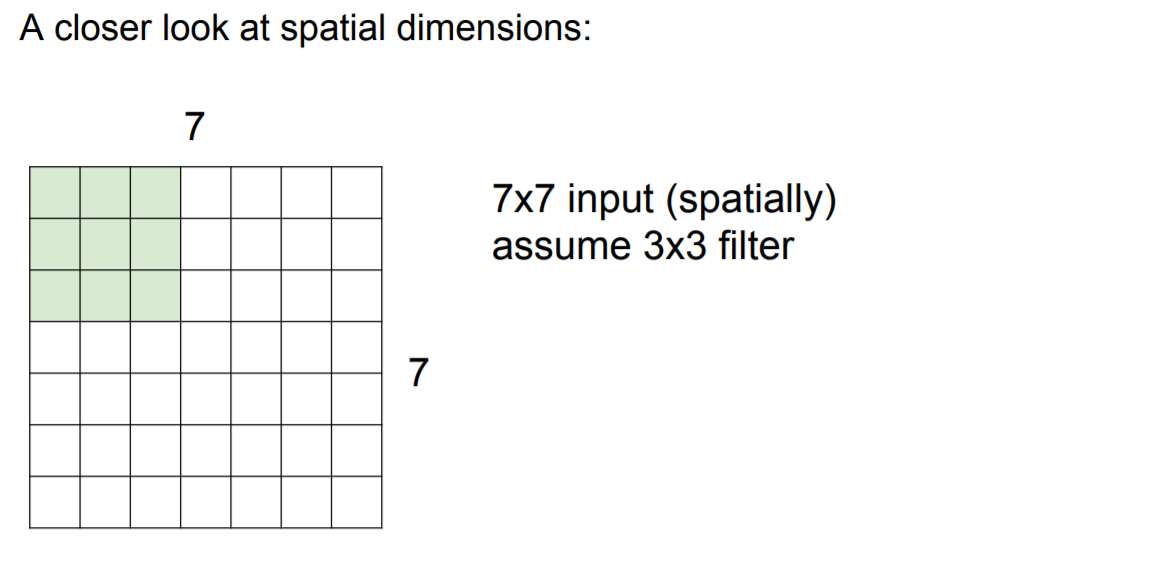
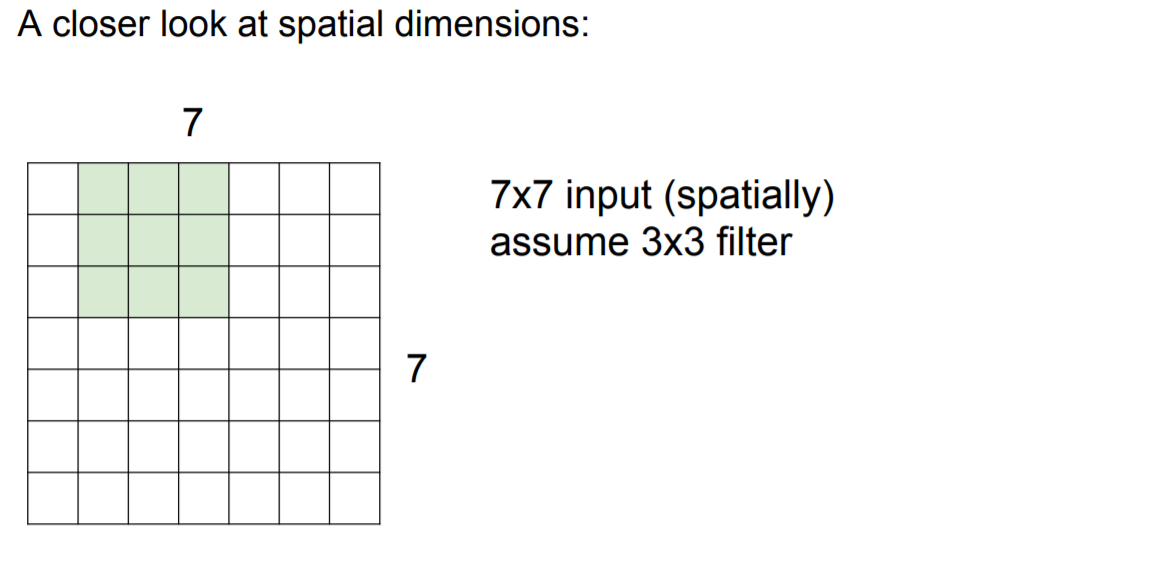
이해를 위해 보다 작은 image(7 x 7)에서의 filter(3 x 3)계산을 진행해보자. (참고: stride = 1)
 |
 |
 |
 |
 |
5 x 5에 해당하는 output이 출력 |
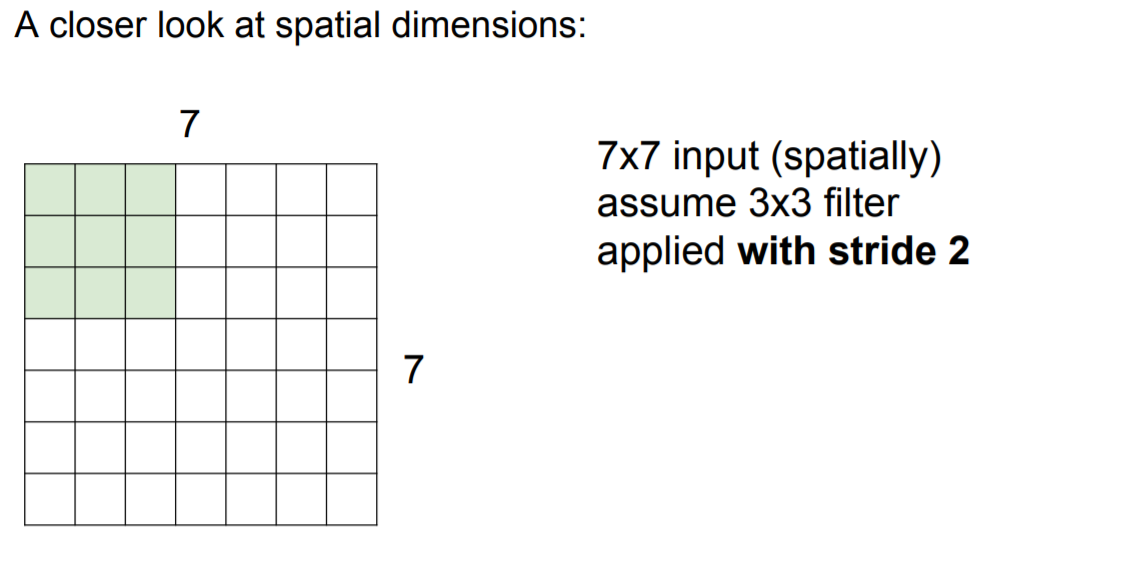
stride = 2인 경우의 filter 계산은 다음과 같다.
 |
 |
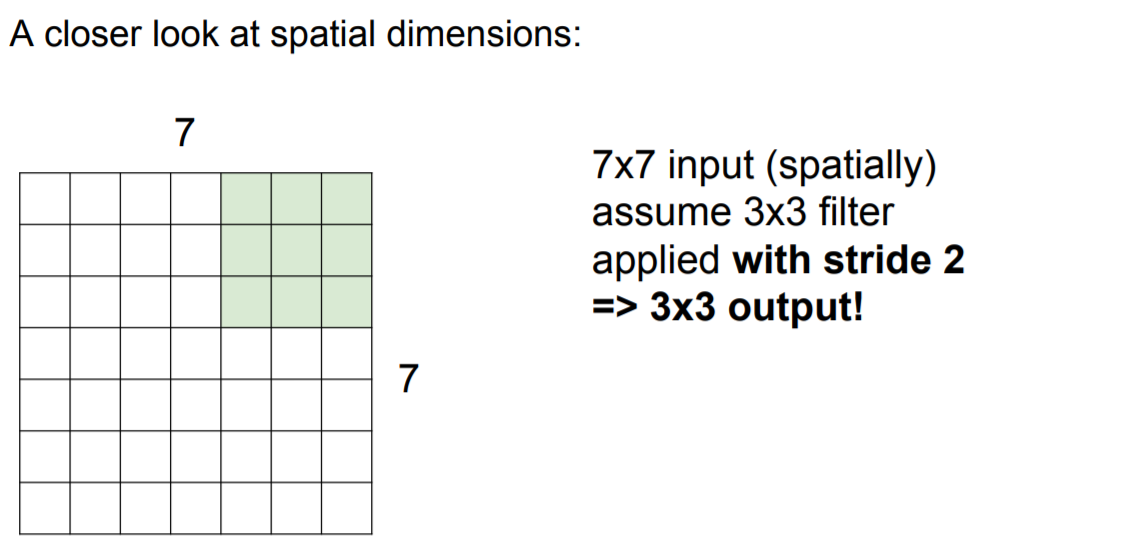 |
3 x 3에 해당하는 output이 출력 (filter가 stop 조건 시작점과 끝점이 각각 마주칠때) |
Q1) stride = 3인 경우에도 적용될까?
 |
 |
A1) 불가능 (이유 : 모서리 부분 정보활용을 못하고 버리게 된다.)
다음은 Output size를 계산해주는 일반화된 공식이다.
 |
input의 크기(N)가 : 7, filter(F) : 3 일 때의 stride를 각각 1, 2, 3 으로 설정하여 계산을 하면 5, 3, 2.33..이 나오게 된다.
문제점
- stride를 거칠 수록 filter map이 계속 작아지게 되는데, image가 급격히 작아지면 cnn층을 얼마 안 쌓아도 image가 없어지게 된다.
- 모서리에 있는 부분이 반영이 상대적으로 덜 가능성이 크다.
즉 정수로 떨어지지 않으면 계산을 진행할 수 없었다. 하지만, zero padding 기법을 이용하면 위 문제점을 해결할 수 있다.
해결방안
- 작아지는 image를 방지하기 위해 zero padding 적용
 |
여기서 또 패딩
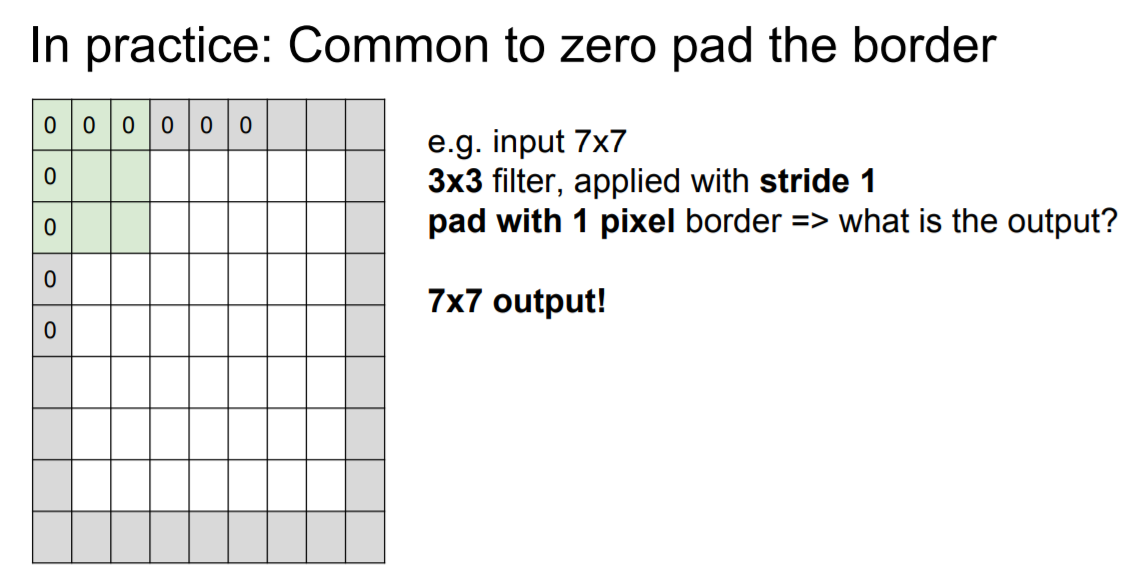 |
 |
일반적으로 filter가 3이면 zero pad는 1번만 적용, filter가 5인 경우 2번 적용
 |
즉, 앞으로 돌아가서 보면 padding을 써야 이미지 크기가 급격히 줄어드는 것을 방지할 수 있다고 한다.
Example 1(Output volume size)
 |
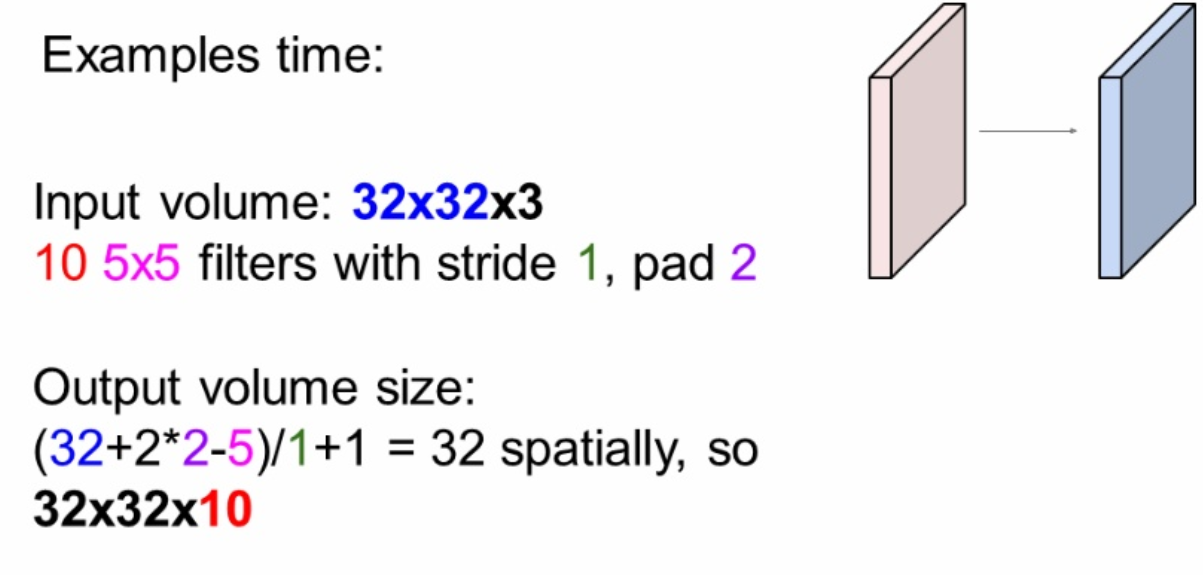 |
Example 2(Number of parameters)
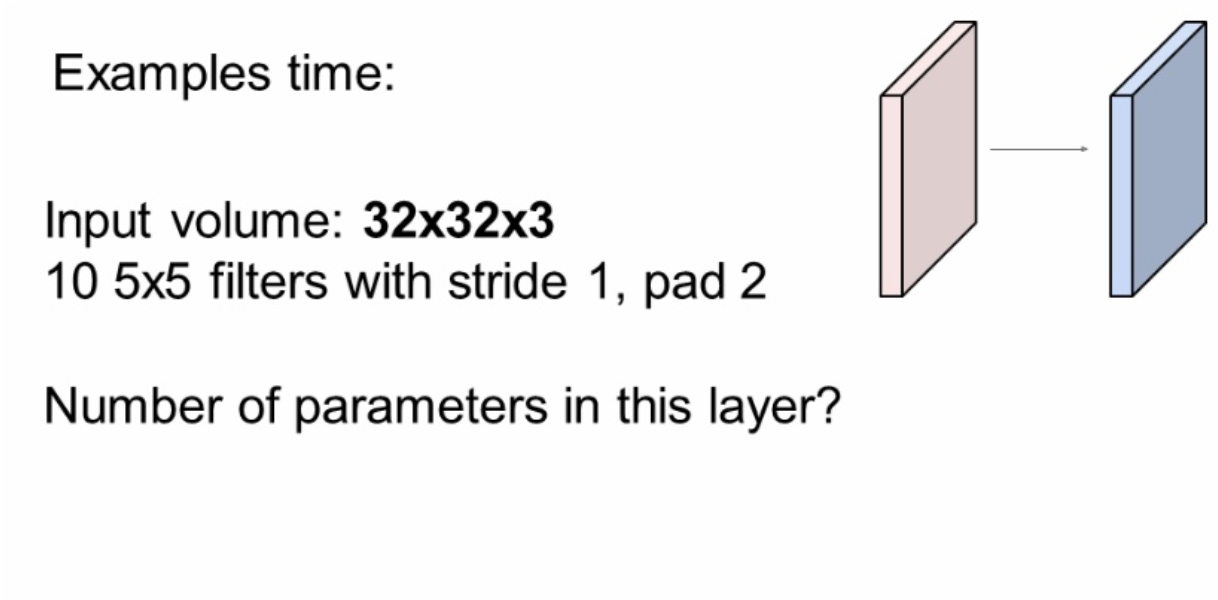 |
 |
Summary : the Conv Layer (알고리즘)
 |
 |
1 x 1 CONV는 기존 input의 width, height를 모두 동일하게 보존하지만, depth에 대해서는 다르게 설정 할 수 있음 (e.g. 64 -> 32, filter 1x1x32 depth 변경), 추가적으로 CNN을 다 거치고나서 Flatten()을 할 때 사용되기도 한다. (즉, FC를 빼고 1x1 CONV를 써도 상관없음)
다음은 torch나 Caffe 라이브러리를 활용해 구현 가능
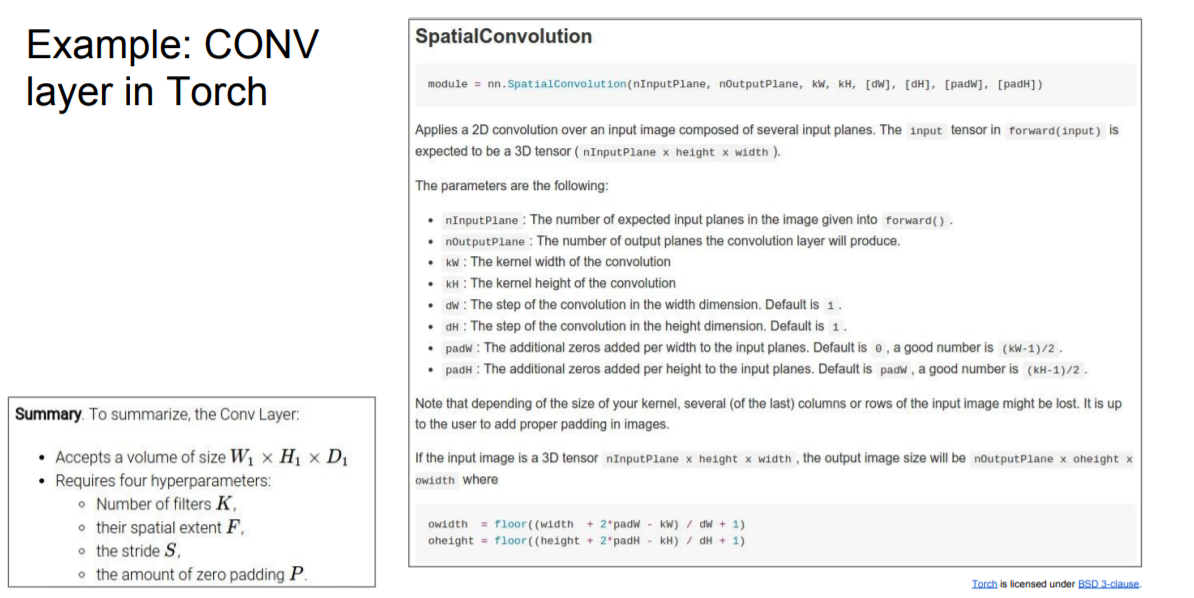 |
 |
 |
 |
local connectivity에 관하여 먼저 말하자면, CNN은 receptive field와 유사하게 local 정보를 활용한다. 공간적으로 이러한 신호들에 대한 correlation 관계를 비선형 필터(activation function)을 적용하여 추출해 낸다. 이런 필터를 여러개 적용하면 다양한 local 특징을 추출할 수 있게 된다. Subsampling 과정을 거치면서 image 및 영상의 크기를 줄이고 local feature들에 대한 filter 연산을 반복적으로 적용하면서 점차 global feature를 얻을 수 있게 된다.
 |
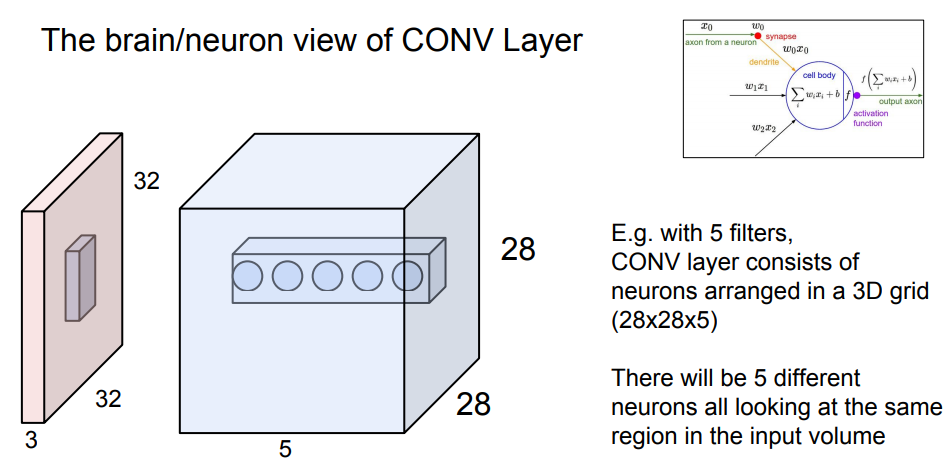 |
서로 다른 filter 5개로 input의 같은 영역에 대해 conv하면 5개의 값들이 위와 같이 나오게 된다. 이렇게 나온 5개의 값들은 각각 다른 특징을 가지고 있을 것이다.
 |
sequence로 최종 label을 출력하기 위해 FC를 걸쳐야 한다. input을 filter map하여, W (가중치 메트릭스)에 내적 , bias추가를 하고 그 값을 activation filter까지 해준다. 기억이 나지 않는다면 Fully Connected Layer를 다시 상기시켜보자.
Pooling Layer
 |
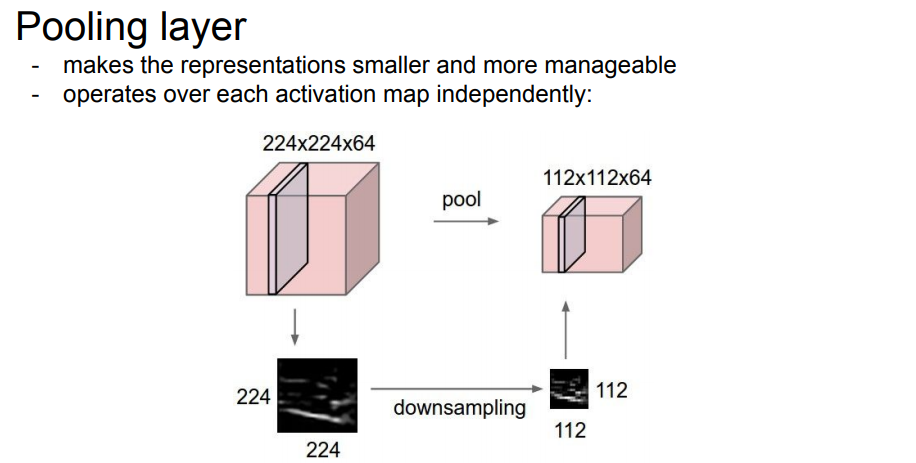 |
- 표현을 작고 관리하기 쉽게 만듭니다.
- 각 활성화 맵에서 독립적으로 작동합니다.
Pooling은 224 x 224 (Width, Height)의 크기를 줄여줄 수 있다. 물론 여기서 filter map의 큰 특징값을 유지하면서 줄이게 된다. 주로 max pooling(영역내에서 큰 값을 대표로 추출)을 많이 사용하며 이외에 average pooling(영역내에서 평균을 대표로 추출)도 존재한다.
 |
4 x 4 에 대하여 max pooling(2 x 2)을 한 결과 위의 오른쪽처럼 2 x 2로 크기가 줄어드는 것이다.
 |
일반적으로 flilter size를 2x2로 적용할때에는 stride도 같이 2로 설정하며, 3x3을 적용하는 경우도 stride를 2로 설정한다고 한다.
 |
최종적으로 FC에서 softmax를 통해 image의 class를 분류하는 과정이다.
https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
ConvNetJS CIFAR-10 demo
cs.stanford.edu
이상으로 5장 내용을 마침
Reference
'CS231' 카테고리의 다른 글
| Lecture 7 : Training Neural Networks II (2) | 2020.04.16 |
|---|---|
| Lecture 6 : Training Neural Networks I (2) | 2020.04.12 |
| Lecture 4 : Backpropagation and Neural Networks (0) | 2020.03.29 |
| Lecture 3 : Loss Functions and Optimization (0) | 2020.03.22 |
| Lecture 2 : Image Classification (0) | 2020.03.22 |




댓글