이번 장에서 다룰 내용들은 다음과 같다.
- Linear classification II
- Higher-level representations, image features
- Optimization, stochastic gradient descent
Lecture 3를 본격적으로 들어가기 전에 Lecture 2의 내용을 잠시 상기시켜보자.
"Challenges of recognition"
 |
"data-driven approach, kNN"
 |
"Linear Classifier"
 |
 |
"cat", "automobile" ,"frog" 3개의 데이터에 대해 "Linear Classifier"로 Score를 구하면 각각 10개의 class에 해당하는 score를 구하고, 그 값이 가장 큰 값에 해당하는 클래스를 구분하는 것까지 "Lecture 2"에서 다룬 내용이다. 이번 시간에다룰 내용은 다음과 같다.
- Loss function : training data를 통해 score를 좋은지, 나쁜지 정량화시킬 수 있는 loss function을 정의
- Optimization : loss function을 최소화하는 parameter를 효율적으로 찾는 방법
Loss function
간단하게 3개의 training (학습데이터)로부터 "f(x, W) = Wx"를 통해 각각 "cat", "car", "frog"에 해당하는 Score를 다음과 같이 얻었다고 가정하자. 정확히 잘 분류(paramter : W 가 좋은지)가 되었는지 정답 관점에서의 score를 보면 다음 아래와 같다. 주어진 f(x, W)를 통해 잘 예측 했는가?
- f(x_cat, W) : 3.2 (False)
- f(x_car, W) : 4.9 (True)
- f(x_frog, W) : -3.1 (False)
 |
 |
Term 정리
- N : loss function에 반영되는 데이터 갯수
- x_i : i에 해당하는 input image (e.g. : x_cat = (width = 32, height = 32, num_channel : 3) shape로 이루어짐)
- y_i : i에 해당하는 label (e.g. : y_cat = 0, y_car = 1, y_frog = 2)
loss function은 주어진 데이터를 내에서 현재 classifier(모델)가 얼마나 좋은지 알려주며, data set(input data N개)에 대한 Loss function은 다음과 같이 일반화할 수 있다.

일반화된 Loss를 활용한 "Multiclass SVM loss"(hinge loss)에 대해 알아보자.
 |
Term 정리
- s_j : 정답이 "아닌" class의 score
- s_yi : "정답" class의 score
- 1 : safety margin
condition
- 만약, s_yi("정답" class의 score)가 s_j("정답이 아닌" class의 score) + 1 보다 크거나 같다면, loss = 0
- 그렇지 않으면(작다면), loss = s_j - s_yi + 1
간단히 말하면, 정답 클래스가 정답이 아닌 클래스보다 safety margin(여기서는 1)보다 크면 loss는 0으로 취급하겠다. loss가 0이라는 것은 매우 좋다는 것이다. 이를 그래프로 나타내면 아래와 같다. 이것을 "Hinge Loss"라고도 부른다.
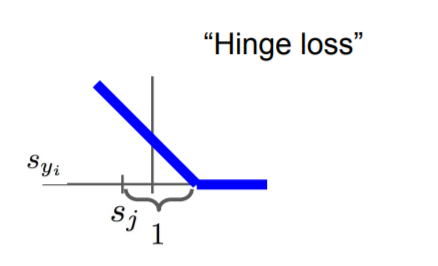 |
이제 Loss를 직접 계산해보자.
 |
sample(3개) 전체의 Loss를 구하기 위해 부분적인 "cat"에 대한 L_cat을 구하는 과정은 다음과 같다.

 |
- L_cat = 2.9
- L_car = 0
- L_frog = 12.9
- 위의 방법으로 나머지 L_i를 구하면 다음과 같다.
따라서, Sample (3개)에 대한 Loss는 아래와 같다.

Q1 : What happens to loss if car scores change a bit?
 |
Q1 : "Car"의 Score가 4.9에서 3.9로 바꾸면 무슨일이 일어날까?
A1 : 그럼에도 불구하고 Loss 관점에서는 0이다. 즉, SVM hinge Loss의 특성이 나오는데, score에 민감하지 않다는 것이다. 즉, "car"의 score가 4.9이거나 3.9인 경우에도, "Car"의 Loss는 0이기 때문이다. 이처럼 SVM hinge Loss은 "score 크기가0 얼마인가"에 관심이 없다. 단지, "정답 클래스가 다른 클래스 보다 높은가"에만 관심이 있다.
Q2 : what is the min/max possible loss?
 |
Q1 : "loss"가 가질수 있는 가능한 min, max는 몇 인가?
A1 : min : 0, max : 무한대
Q3 : At initialization W is small so all s ≈ 0. What is the loss?
 |
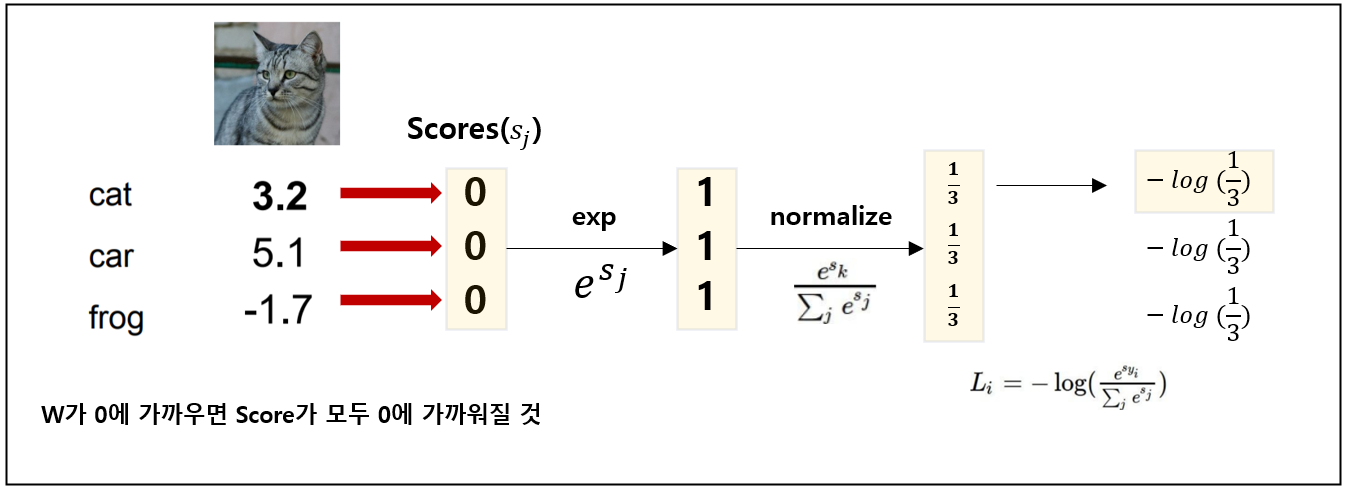
Q3 : W(가중치)를 최대한 작게 하여 score가 0에 근사해지면, Loss는 어떻게 되는가?
A3 : 계산해보자.

좌측은 기존 방법이며, 우측은 W를 아주 작게 한 경우 Loss는 2가 나오는 것을 알 수 있다. 이것을 일반화 시키면 다른 항목에 대해서도 Loss는 C(class 갯 수) - 1 이다. 이처럼 W를 0으로 해주면, Loss가 잘 나오는지 검사를 할 수 있는데, 이 방법을 Sanity Check라고 한다.
Q4: What if the sum was over all classes? (including j = y_i)
 |
Q4 : L_i를 계산할 때 모든 calss를 포함하여 계산하면 어떻게되는가?, 즉, j = y_i, (i=cat, car, frog)
A4 : 계산해보자.

즉, 최종 loss의 평균값이 1 증가하게 되는데, 하지만, 우리는 loss function을 최소화하는게 목적이다. loss가 0이여야 가장 좋다고 해야하는데, 정답 클래스를 포함하여 loss를 계산하면 아무리 최소화하여도 1이 최소값이 된다. 따라서, 정답 클래스를 빼서 loss가 0이 되도록 하는 것이다.
Q5: What if we used mean instead of sum?
 |
Q5 : 각 데이터의 loss를 계산할때 sum 대신 mean을 사용하면 어떠한가?, L_i = mean(x_i)
A5: 평균이기때문에 L_i의 Scale(크기)만 작아진다. 상관 없다.
Q6: What if we used mean instead of sum?
 |
Q6 : L_i에 제곱을 한 경우 어떠할까? hinge loss와 같을까? 다를까?
A6: 제곱을 한 경우 "squared hinge loss"라고 한다. 이는 제곱을 하기 때문에 loss function은 non-linear하며, loss function을 최소화하는 W를 구하는데 잘 적용된다. 제곱의 성질로 인해 정답과 거리가 가까우면 loss를 훨씬 작게, 정답과 거리가 멀다면 loss를 훨씬 더 크게 반영하기 때문에 유용할 것이다.
하지만, 이번 강의에서는 우선 그대로 "hinge loss"를 계속해서 사용할 것이다.
 |
지금까지 설명한 hinge loss는 위 Code로 간단하게 나타낼 수 있다.
Q7: Suppose that we found a W such that L = 0. Is this W unique?
 |
Q7 : L = 0을 만족하는 W를 찾았다 고 가정합니다. 이 W가 Unique(고유)한가?
A7: 정답은 No! 아래 예제를 들어보자. W를 2배하여도 Loss는 0을 만족시킬 수 있음. (Loss는 같음)
 |

지금까지 "W"를 학습하는 과정은 전체 Dataset 중에서 "Training"에 해당하는 Data의 loss를 최소화하는 방향으로 이뤄진다. 하지만 ML에서 model을 만드는 이유는 새로운 Data에 대해서 "예측"을 하기 위해서이다. (Testing으로 정확도를 추출하는 이유) 즉, 학습된 W는 "Tesing"에 해당하는 Data에 안맞을 수도 있다. (W가 Unique하지 않기 때문?) 아래 그림은 위 설명을 시각화하여 설명을 추가하고 있다.
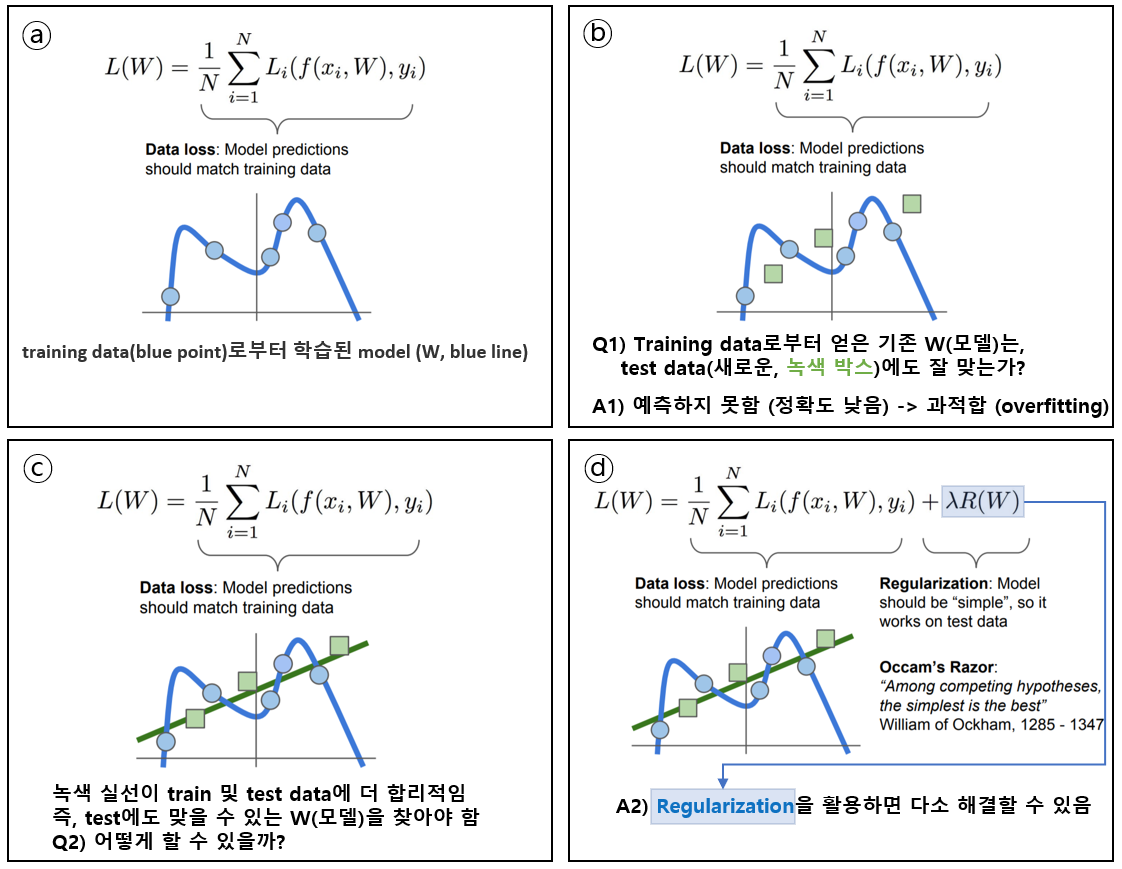
결론을 먼저 말하면 "Regularization"을 사용하면, 다항식이 복잡(깊어짐)해 지지 않도록 방지하게 된다. 특히 ML에서 차수가 깊어지면 차원의 저주가 걸리는데, 이 차원이 깊어지지 않도록 방지하는 것이다. 즉, 머신러닝에서 regularization은 overfitting을 방지하는 중요한 기법중 하나다. 따라서 수식적으로 L1, L2 regularization을 논하자면, 모델을 구성하는 계수(coefficients)들이 학습 데이터에 너무 완벽하게 overfitting되지 않도록 정규화 요소(regularization term)을 더해주는 것
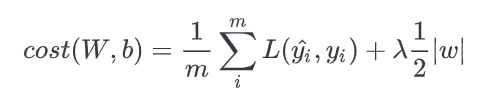 |
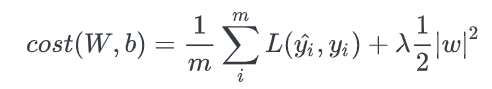 |
- 절대값을 취하는 기법을 쓰냐, L2처럼 제곱합을 취하냐에 따라 L1정규화, L2정규화로 나뉜다. 위는 딥러닝에서 쓴느 loss function에 각각의 정규화를 취한 식이다.
- λ는 얼마나 비중을 줄 것이 정하는 계수다. 0에 가까울수록 정규화의 효과는 사라진다. 적절한 λ 의 값은 k-fold cross validation과 같은 방볍으로 찾을 수 있다.
- "Regularization"은 L1, L2 이외에도 Elastic net (L1 + L2), Max norm regularization, Dropout, Batch normalization, stochastic depth 등이 존재(나중에 강의를 통해 다룰 예정)한다.
 |
L1, L2 Regularization 차이 비교
 |
Softmax Classifier (cross entropy)

위에서 L_i에 "- log"(아래 주황색 Line) 를 취하는 이유는 다음과 같다. Softmax function을 통해 나온 확률이 0에 가까울(정답과 멀어질) 수록 loss 관점에서는 +해야하기 때문에 0 주변에서 무한대로 늘어나는 것을 볼 수 있다. 반대로 Softmax function을 통해 나온 확률이 1에 가까울(정답에 가까움)수록 loss 관점에서는 최소화 시켜야기 때문에 1 주변에서 loss는 0에 가까워지는 것을 알 수 있다. 즉, "-log 함수"는 Loss function와 probability 의미를 반영해주는 적절한 함수이다.

Q1 : What is the min/max possible loss L_i?
 |
A1 : (위 -log 함수 설명 참고)
- min of L_i : 0
- max of L_i : ∞
Q2 : Usually at initialization W is small so all s ≈ 0. What is the loss?
 |
A2 : - log (1/클래스 갯수) [아래 자료 참고]
hinge loss(SVM) vs cross-entropy loss(Softmax)
 |
지금까지 SVM hinge loss와 Cross-Entropy loss을 다뤘다. 크게 차이점은 max를 취하느냐(SVM) 또는 "exp(softamx)" 및 "- log"을 이용하여 loss를 확률로 만드는 것입니다.
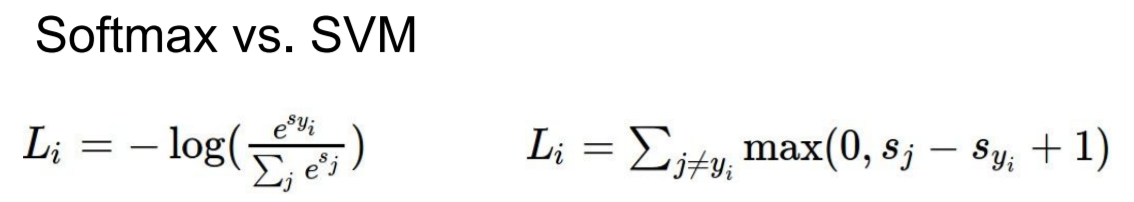
Q1 : Suppose I take a datapoint and I jiggle a bit (changing its score slightly). What happens to the loss in both cases?
 |
A1 : 아래 참고
- Softmax : Score 변화에 민감함(확률로 계산되기 때문에 데이터가 조금만 변해도 확률에 영향을 줌)
- SVM : Socre 변화에 둔감함

Recap
 |
Optimization
 |
Loss Function(Object function)이 존재할때 최솟값(≈0)을 만족하는 W를 찾는 것이다. 이러한 과정을 Optimization이라고 부른다. 어떻게 찾을 수 있는지 고민해보자.
-
A first very bad idea solution: Random search (but, not use)
-
Follow the slope
 |
예제를 통해 gradient를 어떻게 계산하는지 알아보자! (미분 없이 진행함)

위 과정에서 진행한 방법은 매우 Silly(너무 느림)한 방법이다. Loss function은 data와 W로 이루어져 있기 때문에, 미분을 이용하여 구하면 훨씬 효율적으로 구할 수 있다. (감사합니다.)
 |
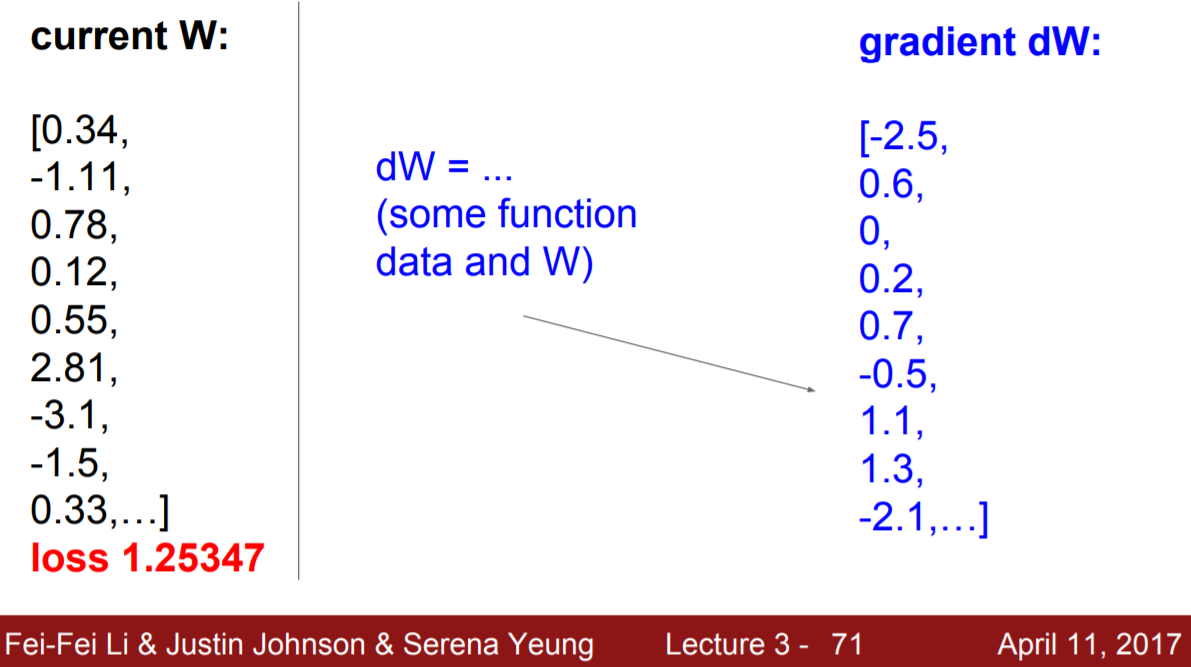 |
In symmary:
- Numerical gradient: approximate, slow, easy to write
- Analytic gradient: exact, fast, error-prone
실제로는 Analytic gradient 을 활용
Gradient Descent
 |

Gradient Descent는 Training Set의 갯수 N을 한번에 계산하는 과정이다. 만약 N이 수천만개 일 때, 계산을 하려면 시간이 많이 걸리므로 비효율적이다. (W가 한번 업데이트 되려면 처음부터 끝까지 계산을 하고 업데이트)
위의 문제점을 해결하기 위해 SGD를 많이 사용한다. minibatch(전체 dataset을 나눔, sample = 256, 512 etc)를 사용하면 계산 data 수가 적기 때문에, 빠르게 W를 업데이트 할 수 있다.
Stochastic Gradient Descent (SGD)
 |
Gradient Descent vs SGD vs Minibatch GD
수업 시간에 다룬 내용 바탕으로 다시 한번 정리를 하면 다음과 같다. 엄밀히 따지면 MSGD 와 SGD 는 다른 알고리즘이지만 요즘엔 MSGD를 그냥 SGD라고 많이들 혼용해서 부른다. 그래서 Ian Goodfellow 책에서도 아래 그림처럼 MSGD 알고리즘을 설명할 때 SGD 라고 표현하고 있다. (출처: https://light-tree.tistory.com/133 [All about])
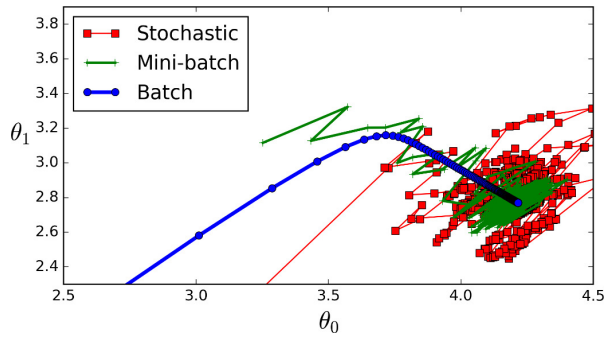
gradient(기울기)를 구하기 위해 모듈에 data를 넣을텐데, 세 가지 방법이 어떻게 학습을 하는지 아래 그림으로 비교해보자. (단, 전체 학습(Train) 데이터를 1000개, 학습 횟수(Epoch)는 1로 가정)
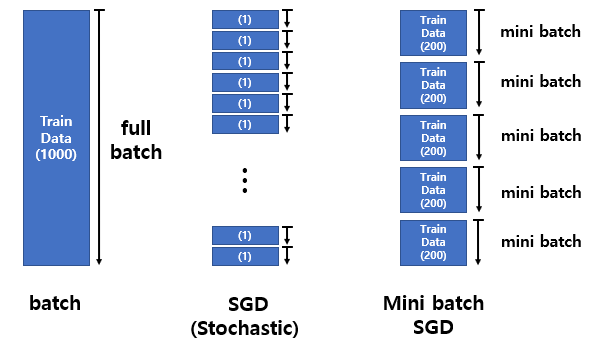
- batch : 1000개의 data를 한번에 넣어야하기 때문에, 학습이 오래 걸리는 단점이 존재함
- SGD : batch의 문제점을 해결한 SGD는 sample을 한개씩 넣어 학습하는데, 이는 batch보다 계산하는 시간은 빠르지만, parameter가 아래 그림(빨강선)처럼 튀는 현상이 발생한다. (수렴하기 어려움)
- Mini batch : batch와 SGD의 문제점을 해결함 sample 200개를 한번에 뽑아 학습 시키는 방법
 |
 |
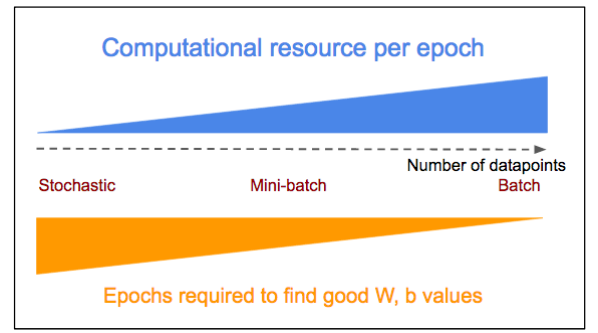
image features : Motivation

|
 |
 |
 |
지금은 ConvNets 을 활용하여 Image 문제를 다루고 있다.
 |
Reference
Stanford University CS231n: Convolutional Neural Networks for Visual Recognition
Can I audit or sit in? In general we are very open to sitting-in guests if you are a member of the Stanford community (registered student, staff, and/or faculty). Out of courtesy, we would appreciate that you first email us or talk to the instructor after
cs231n.stanford.edu
'CS231' 카테고리의 다른 글
| Lecture 7 : Training Neural Networks II (2) | 2020.04.16 |
|---|---|
| Lecture 6 : Training Neural Networks I (2) | 2020.04.12 |
| Lecture 5 : Convolutional Neural Networks (3) | 2020.04.03 |
| Lecture 4 : Backpropagation and Neural Networks (0) | 2020.03.29 |
| Lecture 2 : Image Classification (0) | 2020.03.22 |



댓글