이번 장에서 다룰 내용들은 다음과 같다.
- Backpropagation(오차역전파)
- Neural Network(신경망)
Lecture 4를 본격적으로 들어가기 전에 Lecture 3의 내용을 잠시 상기시켜보자.
 |
지금까지 했던 계산(loss, gradient descent 등등)들을 graph 형태로 정리할 수 있었는데 이를 "Computational graphs"라고 합니다. 이는 이번장에서 다룰 "Backpropagation"에 매우 유용하다고 합니다. "Backpropagation"이 어떻게 수행되는지 알아 볼 것이다.
아래처럼 더 확장하여 Layer를 다음과 같이 쌓아 복잡한 네트워크를 구성한 예제들이 있는데, 복잡한 모델도 "Computational graphs" 원리를 이용해 "Backpropagation"을 작동시 킬 수 있다.
 |
Backpropagation (오차역전파)
아래의 예제1 를 통해 "chain rule"을 활용한 "gradient"를 구하는 방법을 이해해보자.
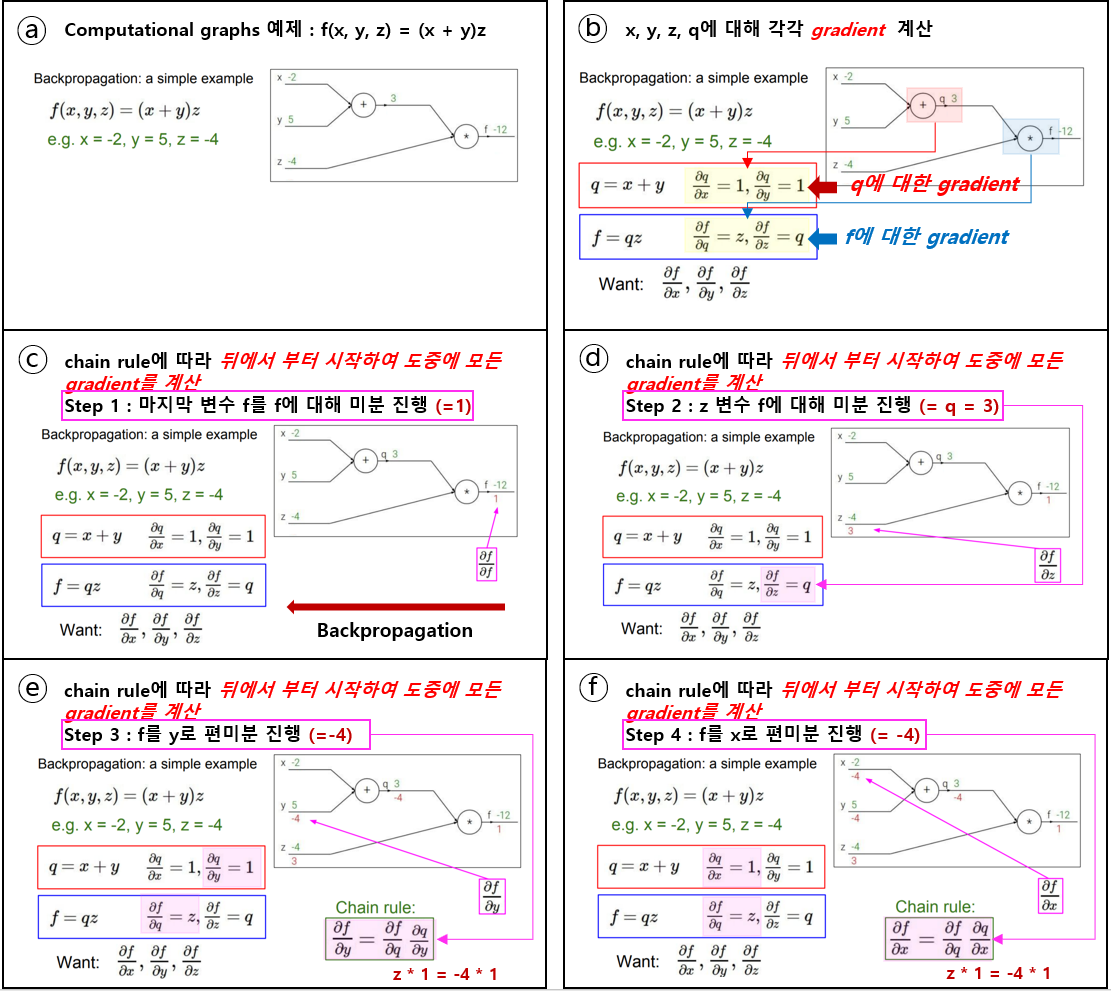
f에 대해 x, y, z 각각에 대한 gradient를 chain rule을 이용하여 쉽게 구할 수 있었다.
하지만, 위에서 qx나 x+y에 와 같이 결합된 함수에 대해서도 미분을 진행하였었는데, 이 때의 미분 값을 "local gradient"라고 부른다.
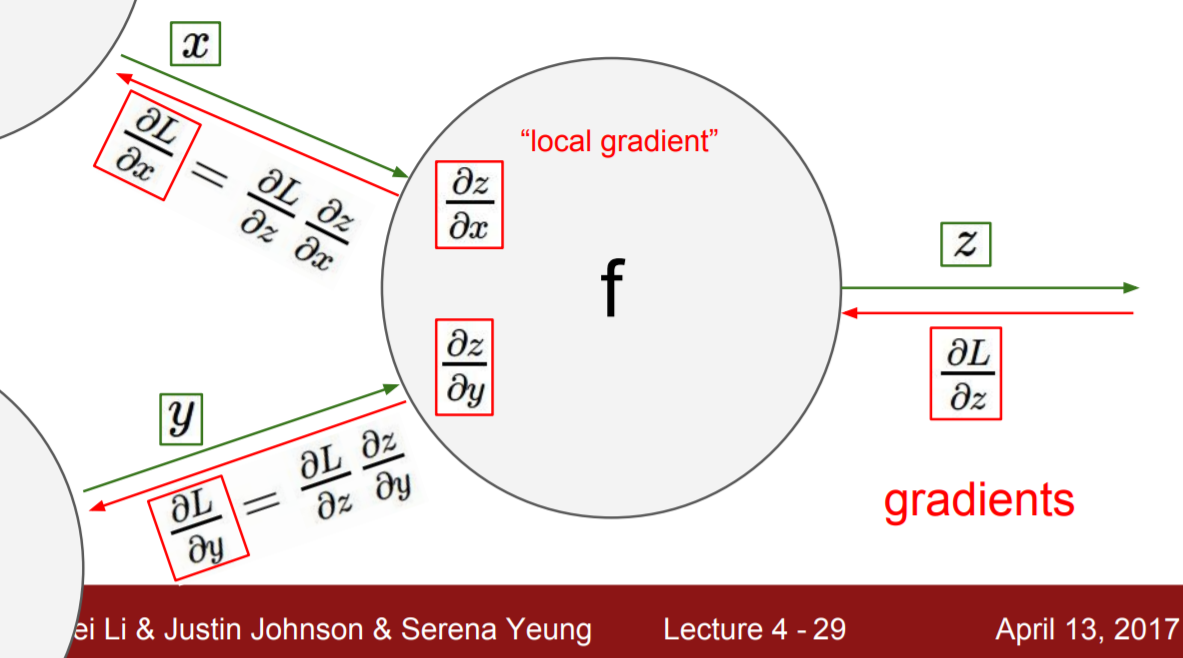 |
아래의 예제2 를 통해 "chain rule"을 활용한 "gradient"를 구하는 방법을 이해해보자.
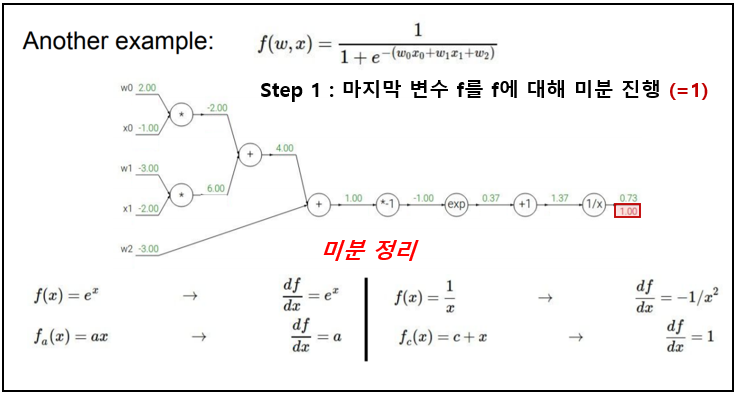 |
 |
 |
 |
 |
 |
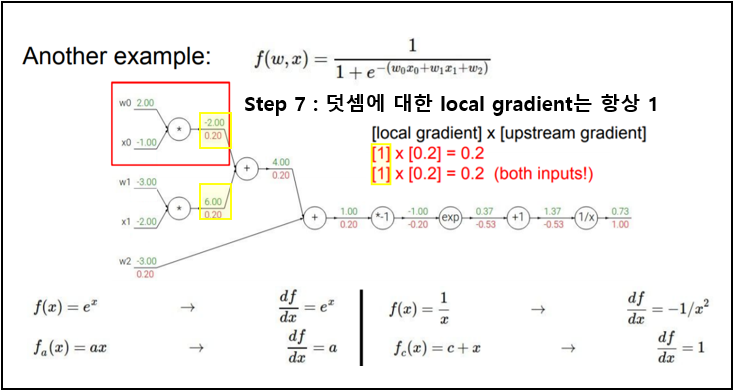 |
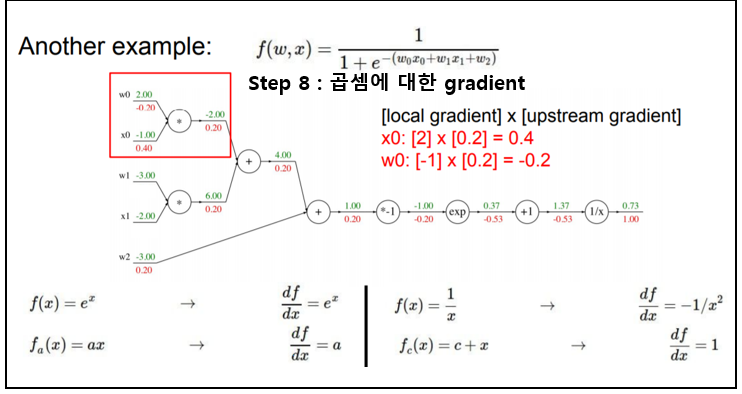 |
위 과정을 잘 살펴보면 "sigmoid function(sigmoid gate)"이 포함되어 있었다. sigmoid 함수를 x에 대하여 미분을 진행하여도 위의 과정과 동일함을 보인다. (굳이 위와 같이 step 별로 나누어서 진행하지 말고 아래와 같이 효율적으로 계산하자)
 |
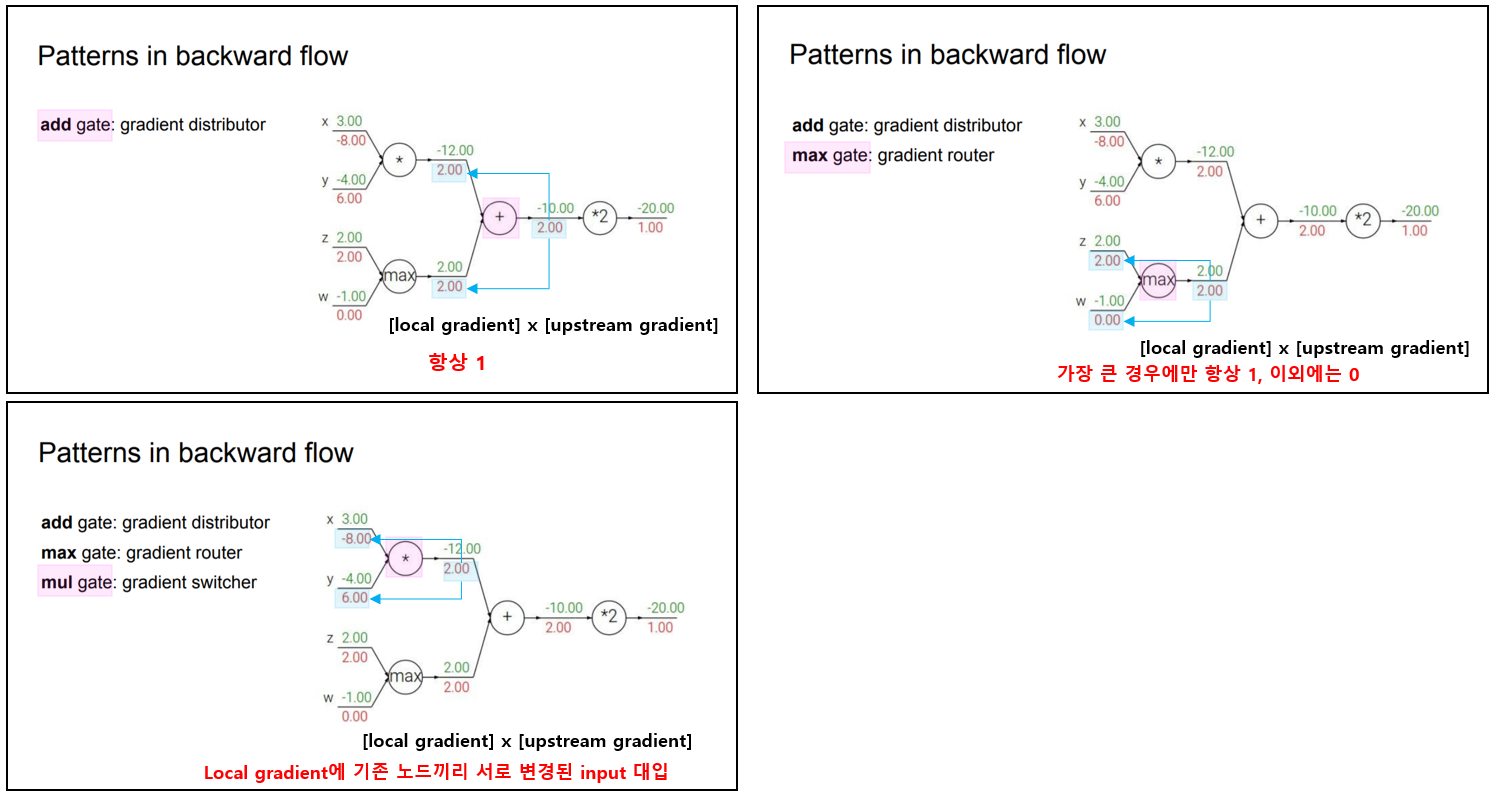
Patterns in backward flow
예제를 통해 계산 그래프에 대해 backpropagation을 진행하다보면 사친연산(add, max, mul)에 대한 패턴이 있다는 것을 알 수 있을 것이다. 정리하면 다음과 같다.
Gradients add at branches
Q : 지금까지는 "upstream gradient"가 하나만 들어오는 경우만 보았지만, 만약, 아래 그림처럼 두 개 이상인 gradient가 들어오면 어떨까?
A : 여러 개의 gradient를 더해 준다.
 |
Gradients for vectorized code
지금까지 이해를 돕기 위해 간단한 scalar에 대한 계산을 진행하였지만, 앞으로는 확장하여(일반화) vector에 대한 계산을 할 것이다. 그리고, vector에 대한 backpropagation을 하려면, 단일 미분이 아닌 모든 요소에 대한 미분을 위한 "Jacobian matrix(다변량 함수의 미분값)"를 활용하면 된다. (chain rule 원리는 동일)
 |
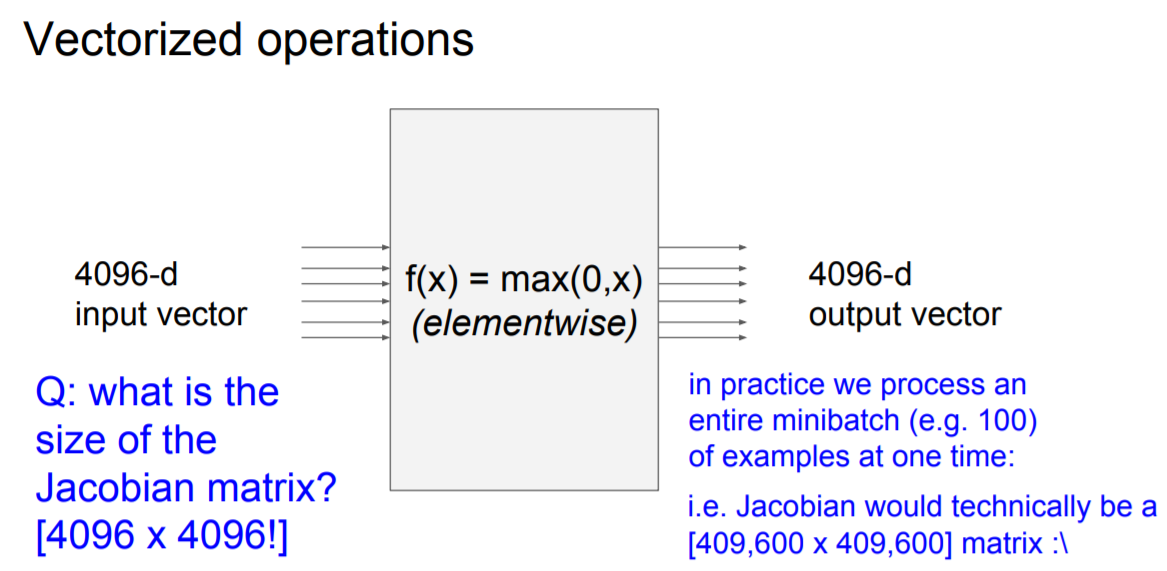 |
Q1 : what is the size of the Jacobian matrix?
A1 : 아래와 같음
- input 갯수가 1개인 경우 (batch size = 1) : [4096 x 4096]
- input이 100개인 경우 (batch size = 100) : [409,600 x 409,600]
실제로 위의 matrix를 계산하기 위해서는 많은 연산이 필요할 것이다. 하지만, 그럴 필요가 없음
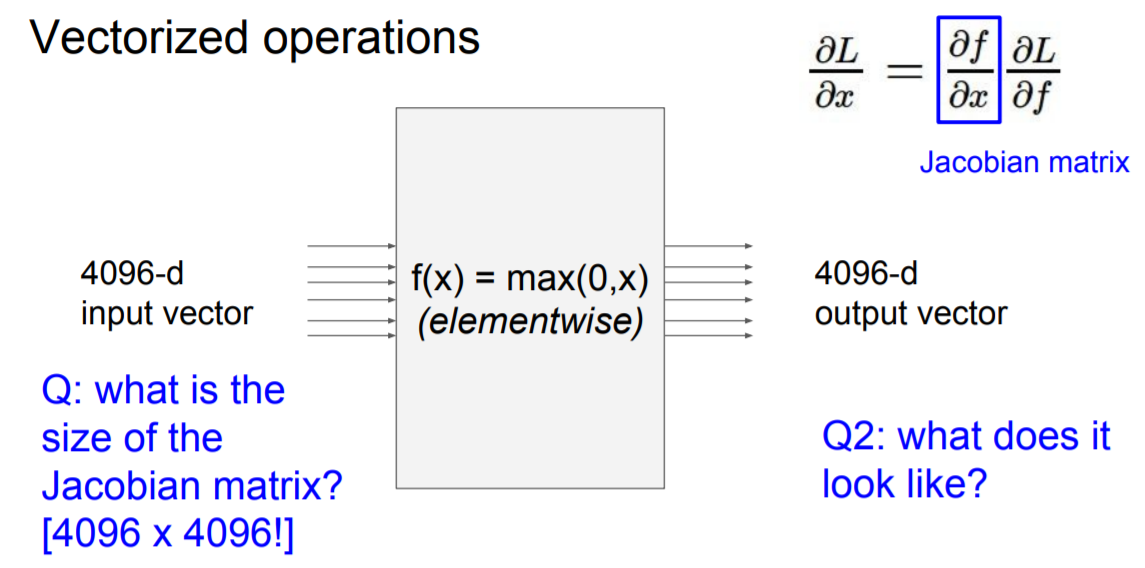 |
Q2 : what does it look like?
A2 : element 별로 행렬을 보기때문에 input의 각 element에만 출력에 영향을 줄것이다. 대각행렬만 고려하면 된다. 그리고 계산된 gradient는 대각행렬에 채워 넣기만 하면 된다.
vector 예제를 직접 풀어보면서 이해해보자.
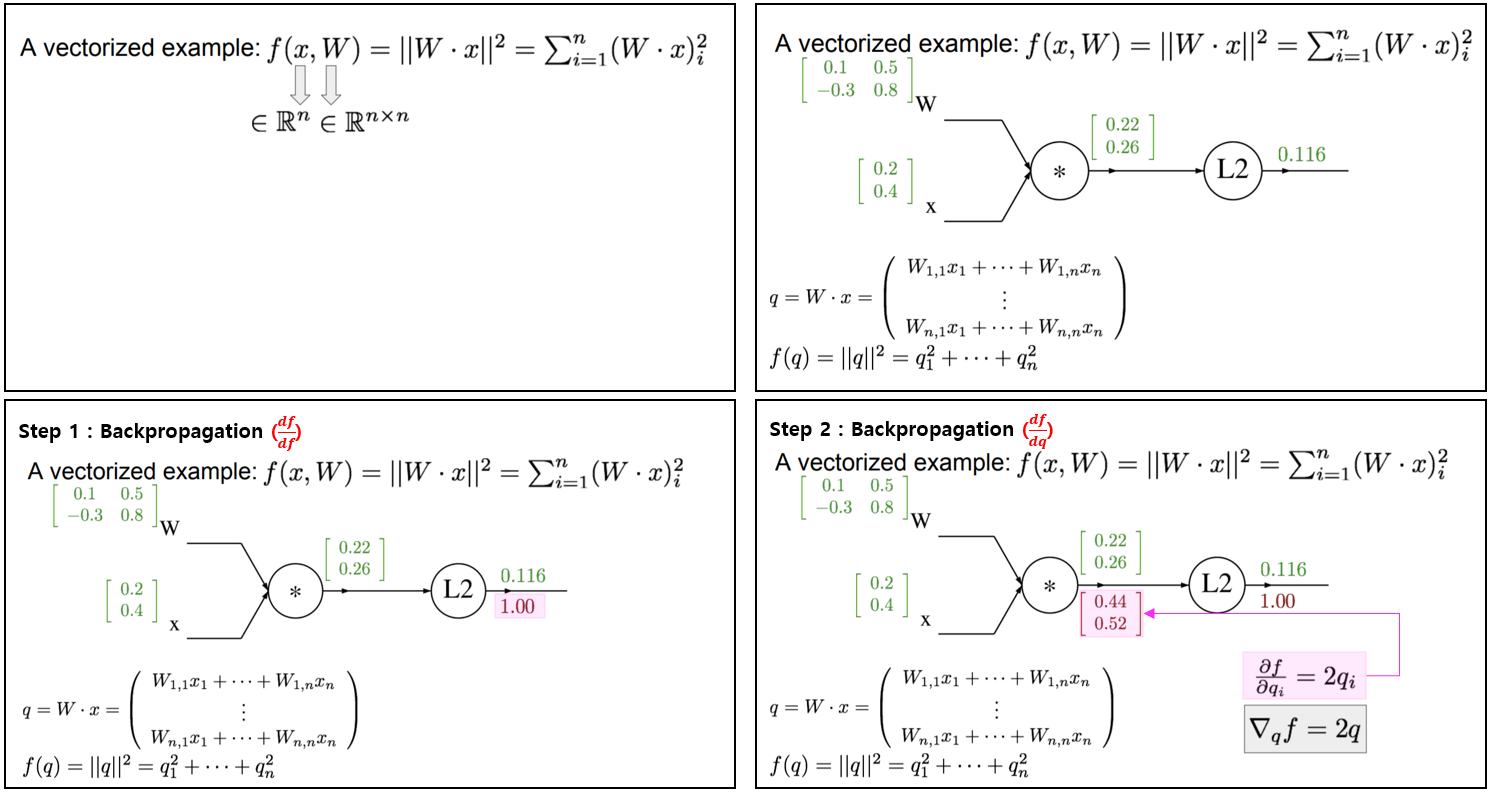  |
주의 : 각 변수의 gradient의 shape는 변수의 shape와 같아야 한다.
- shape of W (2 x 2) == shape of gradient_W (2 x 2)
- shape of x (2 x 1) == shape of gradient_x (2 x 1)
- shape of q (2 x 1) == shape of gradient_q (2 x 1)
- shape of L2 (1) == shape of gradient_L2 (1)
Modularized implementation: forward / backward API
지금까지 해왔던 것을 code로 간단하게 구현하는 과정은 다음과 같다.
   |
Neural Networks
지금까지 f = Wx(단순한)에 대한 score 구해왔다. 더 나아가 ReLU(non-linear)라는 함수를 거친 W2를 추가한 layer를 추가해보자.
 |
input(3072)인 x가 들어오면 W1과 곱을 통해 h(hidden)로 들어가고 이 h를 통해 나와서 class가 10개인 output을 나오게 된다.
즉, 기존과 달리 h가 하나 더 생기게 되었다. 이것은 과거에 하나의 분류기로 판단했던 것과 물리적 구조 및 의미가 다르다. h가 100개면 우리는 서로 다른 100개의 분류기를 가지고 있는 것과 같다.
코드는 생략!
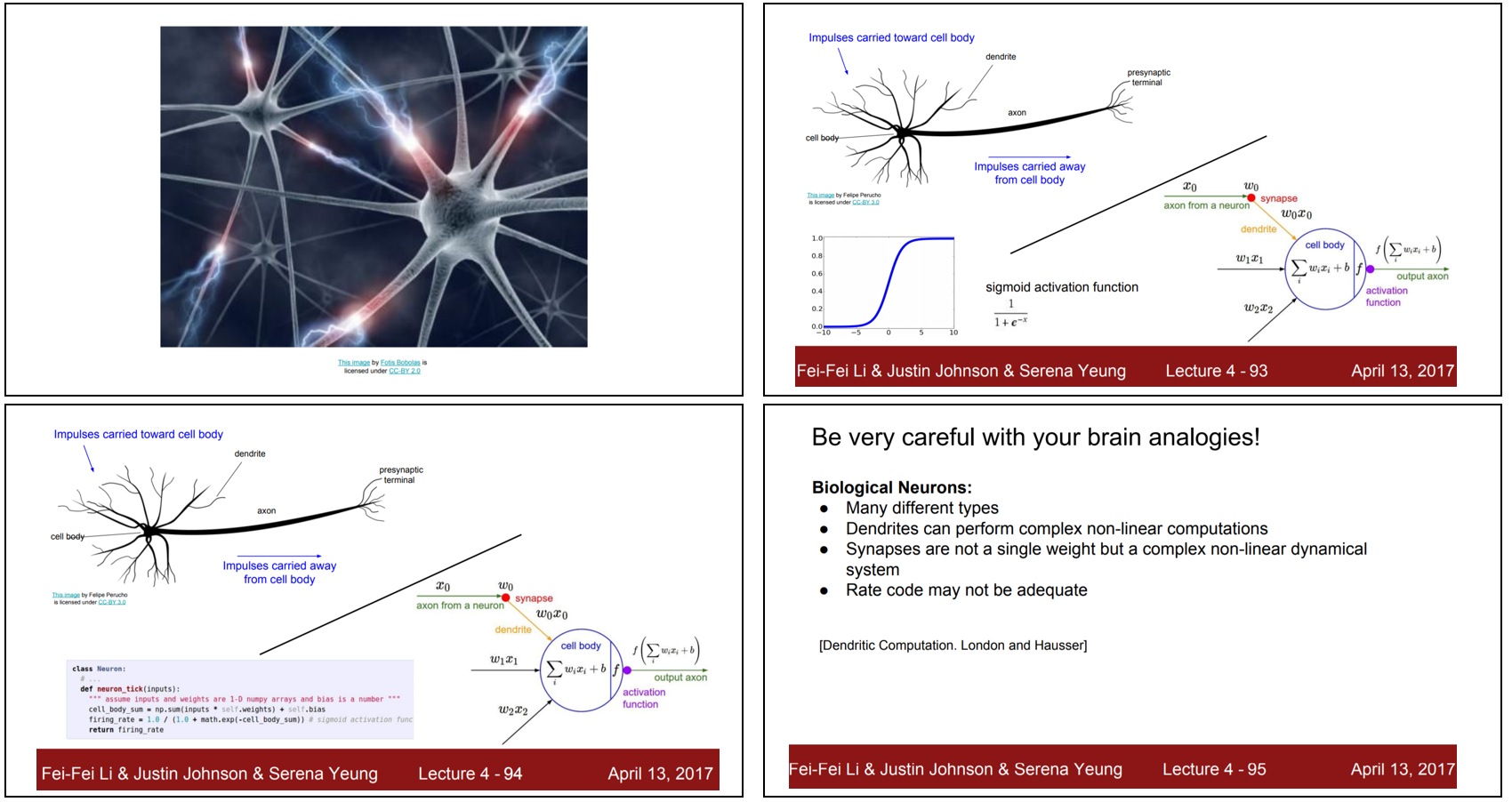 |
우리 뇌속의 뉴런의 원리를 모방하여 network를 만든것 (code 포함), 하지만 실제 생물학 뉴런은 많이 다르고, 실제와 원리는 많이 다르기 때문에, 딥러닝에서 만들어지는 network는 실제 신경망과 같다고 판단하면 안된다고 한다.
Activation Functions
 |
지금까지 sigmoid 및 ReLU를 배웠지만, 더 다양한 Activation Functions이 존재한다.
Neural networks: Architectures
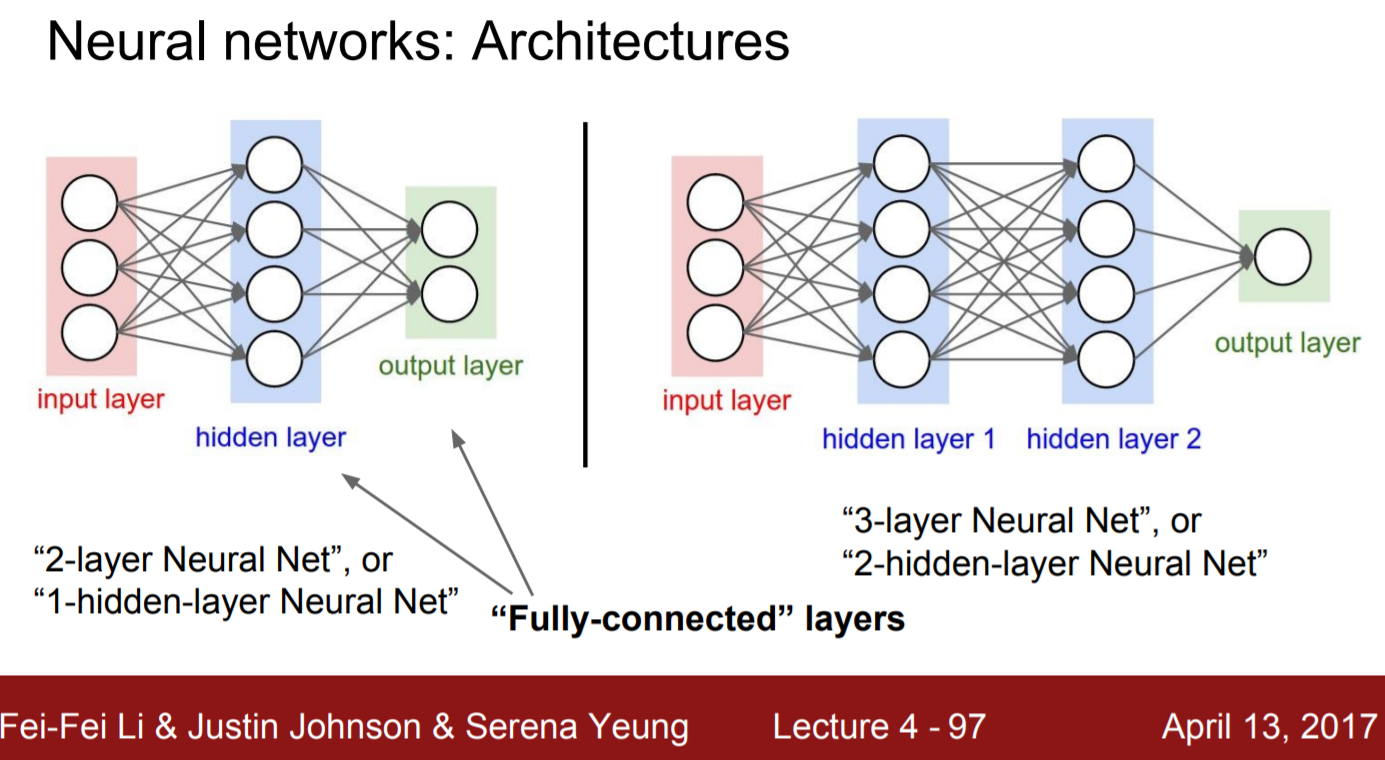 |
 |
'CS231' 카테고리의 다른 글
| Lecture 7 : Training Neural Networks II (2) | 2020.04.16 |
|---|---|
| Lecture 6 : Training Neural Networks I (2) | 2020.04.12 |
| Lecture 5 : Convolutional Neural Networks (3) | 2020.04.03 |
| Lecture 3 : Loss Functions and Optimization (0) | 2020.03.22 |
| Lecture 2 : Image Classification (0) | 2020.03.22 |



댓글