2020-2학기 서강대 김경환 교수님 강의 내용 및 패턴인식 교재를 바탕으로 본 글을 작성하였습니다.
9.5 Resampling for classifier design
▶ A number of general resampling methods that have proven effective when used in conjunction with any in a wide range of techniques for training classifiers.
앞 절에서 기존 분류기의 정확도를 포함해서 통계량을 추정할 때의 resampling의 사용을 다루었으나, 분류기들 자체의 설계는 간접적으로만 언급했다. 이제 분류기를 resampling기법과 결합하여 효과가 입증된 방법들을 살펴보자. 추후 Ch9.6에서 논의할 분류기 모델들을 추정하고 비교하기 위한 방법들과 관계가 있다.
9.5.1 Bagging
▶ Arcing
- the generic term - adaptive reweighting and combining (적응적 재가중 및 결합)
- refers to reusing or selecting data in order to improve classification. (분류기를 향상시키기 위해 데이터를 재사용/선택을 의미)
▶ Bagging - "Bootstrap aggregation"
- Uses multiple versions of a training set, each created by drawing $n’ \lt n$ samples from $D$ with replacement.
- Each of the bootstrap data sets is used to training a different component classifier and the final classification decision is based on the vote of each component classifier
- Bagging is our first encounter with multiclassifier systems
부트스트랩 집합에서 온 이름이며, 훈련 집합의 여러 버전을 사용하는데, 각 버전은 $D$로부터 $n' \lt n$개의 샘플을 뽑아서(뽑힌 것을 다시 넣고 뽑는 방식으로) 생성된다. 이 부트스트랩 데이터 집합의 각각은 다른 요소 분류기를 훈련시키는 데 사용되며, 최종 분류 판정은 각 요소 분류기의 투표에 기반함. Bagging은 최종 전체적 분류기가 여러 요소 분류기의 출력에 기반하는 다중분류기 시스템이다.
9.5.2 Boosting
- The goal is to improve the accuracy of any given learning algorithm.
- We first create a classifier with accuracy on the training set greater than average.
- Then we add new component classifiers to form an ensemble whose joint decision rule has arbitrarily high accuracy on the training set. – we say that the classification performance has been “boosted.”
- The technique trains successive component classifiers with a subset of the training data that is most informative given the current set of component classifiers.
- Classification of a test point $\mathbf{x}$ is based on the output of the component classifiers
부스팅의 목적은 임의의 주어진 학습 알고리즘의 정확도를 개선하는 것이다. 부스팅에서 훈련 집합에 대한 정확도가 평균 이상인 분류기를 만들고, 결합 판정 룰이 훈련 집합에 대해 임의로 높은 정확도를 갖는 앙상블을 형성하기 위해 새로운 요소 분류기들을 추가한다. 그러한 경우, 분류 성능이 부스팅 되었다고 말한다. 이 기법은 요소 분류기들의 현재 집합이 주어졌을 때 연속하는 요서 분류기들을 "가장 정보제공적인" 훈련 데이터의 부분 집합으로 훈련시킨다. 아래서 보겠듯이, test point $\mathbf{x}$의 분류는 요소 분류기들의 출력들에 기반함
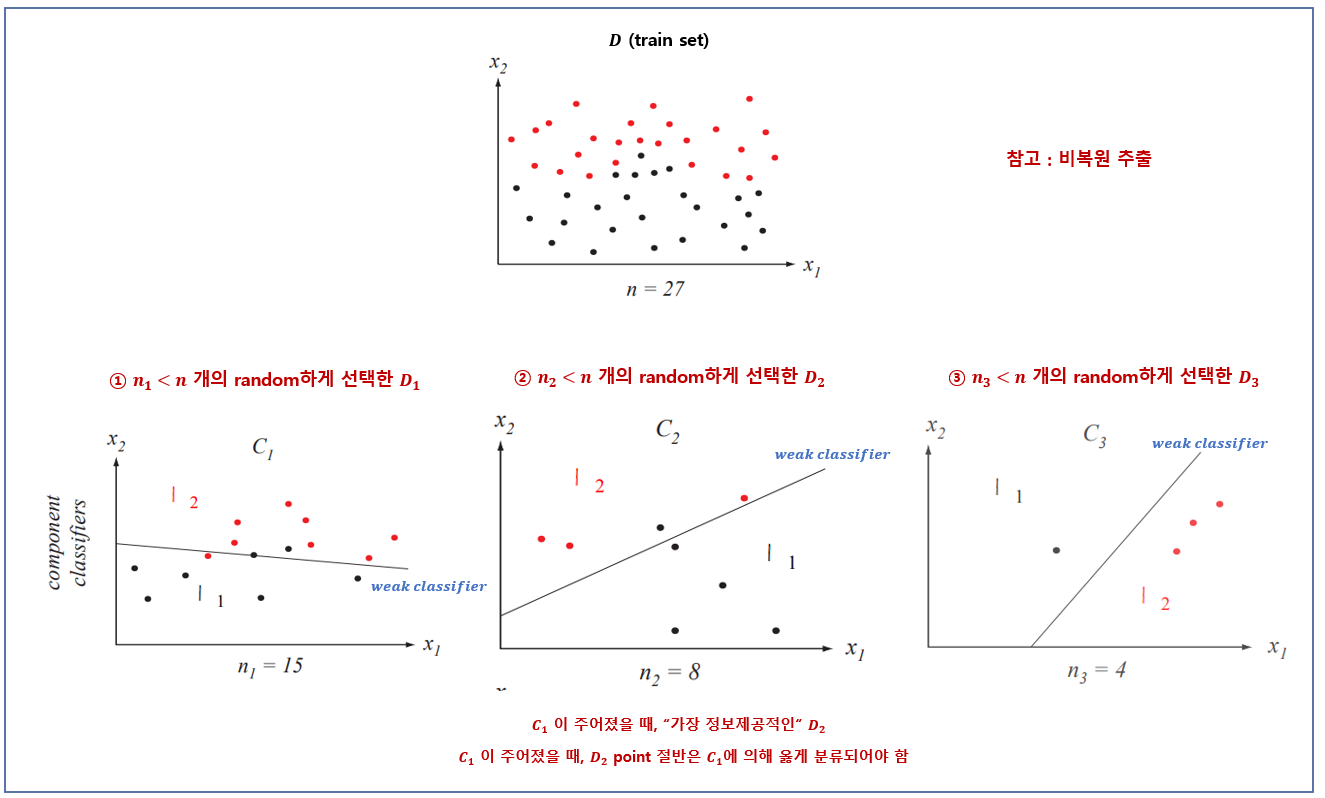
▶ AdaBoost - adaptive boosting
- The most popular variation of the basic boosting.
- To allow the designer to continue adding weak learners until some desired low training error has been achieved.
- Each training pattern receives a weight that determines its probability of being selected from a training set for an individual component classifier.
- If a training pattern is accurately classified, then its chance of being used again in a subsequent component classifier is reduced.
- If the pattern is not accurately classified, then its chance of being used again is raised.
- AdaBoost focuses in on the informative or difficult patterns
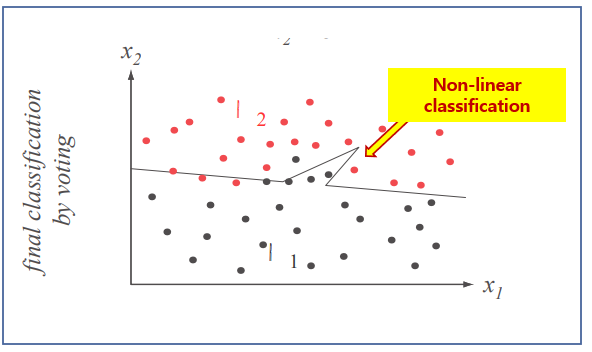
- The final classification decision of a test point x is based on a discriminant function that is merely the weighted sums of the outputs given by the component classifiers.
기본적인 부스팅의 여러 변형이 있다. 가장 인기 있는 것이 AdaBoost이다.
원하는 낮은 훈련 에러를 달성할 때까지 설계자가 약한 학습자들을 추가하는 것을 계속해서 허용한다.
AdaBoost에서 각 훈련 패턴은 개별 요소 분류기를 위한 훈련 집합에 선택될 확률을 결정하는 가중치를 받는다.
만일 어떤 훈련 패턴이 정확하게 분류된다면, 다음 요소 분류기에 다시 사용될 기회는 줄어들 것이다.
반대로, 만일 어떤 훈련 패턴이 정확하게 분류되지 못한다면, 다시 사용될 기회는 증가한다.
이런 방식으로 AdBoost는 정보제공적 또는 "어려운" 패턴들에 "집중"한다. 구체적으로 가중치들을 훈련 집합에 걸쳐 균일하게 초기화한다. 각 반복 $k$에서는 이 가중치들에 따라서 훈련 집합을 랜덤하게 뽑으며, 요소 분류기 $C_k$에 의해 오분류된 훈련 패턴들의 가중치를 증가시키고, $C_k$에 의해 옳게 분류된 패턴들의 가중치는 감소시킨다. 이 새로운 분포에 따라서 선정된 패턴이 그 다음 분류기인 $C_{k+1}$을 훈련시키는데 사용되며, 이 프로세스는 계속 반복된다.
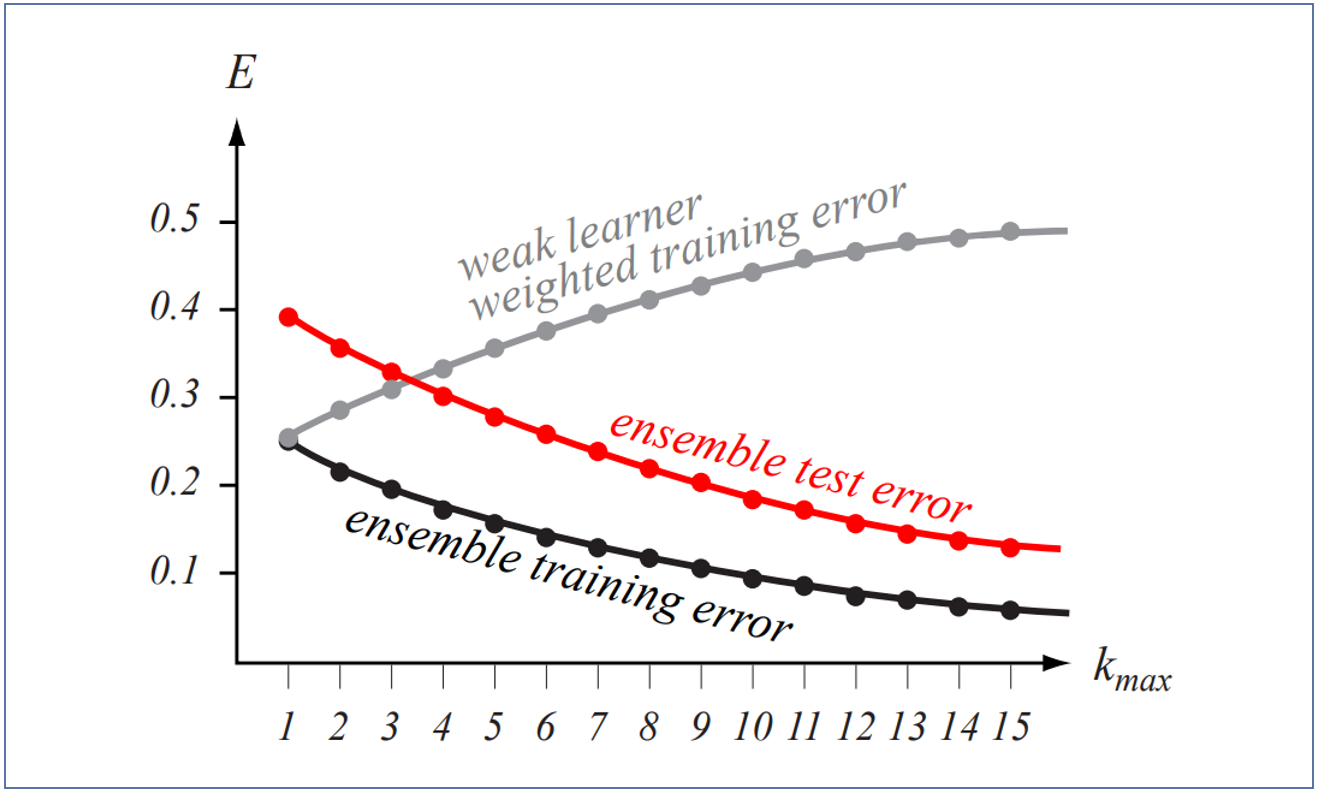
- Weak learner weighted training error 가 증가하는 이유 : 개별적인 classifier이므로 당연히 증가할 수 밖에 없음
9.5.3 Learning with queries
- To determine which unlabeled patterns would be most informative (i.e., improve the classifier the most) if they were labeled and used as training patterns.
- Learning with queries, active learning, interactive learning, cost-based learning
앞 절들에서는 레이블링된 훈련 패턴들의 집합 $D$가 있다고 가정했으며, 분류를 향상시키기 위해 패턴들을 재사용하는 재표본화 방법을 사용했다. 그러나 어떤 응용들에서는 데이터가 레이블링되지 않는다. 여기서는 어떠한 데이터든 레이블링하는 어떤방법이 존재한다고 가정한다. 따라서 지금 해야할 것은 만일 레이블링되지 않은 패턴들이 레이블링되고 훈련 패턴들로서 사용된다면 어떤 것들이 가장 정보제공적인가(즉, 분류기를 가장 개선시키는가)를 결정하는 것이다.
가정 : 어떤 데이터든지 에러 없이 레이블링할 수 있는 선생님인 "oracle"에게 질의를 하여 레이블링을 받는다.
깊게 들어가지는 못하고, 대략적인 방법은 다음과 같음

위에서 진행된 절차를 반복하면 분류기(classifier)를 더 개선시킬 수 있을 것이다. 위와 같은 방법을 "Learning with queries"라고 한다.
더 나아가 두 개의 레이블링된 패턴을 보간하거나 도메인 특유의 어던 방법으로든 섞어서 "중간적인" 새로운 패턴을 생성할 수도 있다고 한다. 그렇게 만든 질의 패턴들로 분류기는 가장 덜 확신하는 특징 공간 영역들을 조사함으로써 error를 줄여나갈 수 있다.
9.5.3 Arcing, Learning with Queries, Bias and Variance
- In many other places, we have stressed the need for training a classifier on samples drawn from the distribution on which it will be tested.
- Resampling seems to violate this recommendation.
지금까지 여러 곳에서 분류기가 테스트될 분포로부터 추출된 샘플들에 대해 분류기를 훈련시킬 필요성을 강조해왔다.
- In broad overview, resampling, boosting and related procedures are heuristic methods for adjusting the class of implementable decision functions.
- As such they allow the designer to try to match the final classifier to the problem by indirectly adjusting the bias and variance.
- The power of these methods is that they can be used with an arbitrary classification technique.
넓게 볼 때, resampling, boosting 그리고 관련된 프로시저들은 구현 가능한 판정 함수들의 클래스를 조정하기 위한 heuristic 방법들이다. 그렇기 때문에, 모델링하는 사람이 bias와 variance를 간접적으로 조정해서 최종 분류기를 문제에 "맞추기 위해" 시도하는 것을 허용하는 것이다. 이러한 방법들의 장점은 다른 방법으로는 임의의 문제의 복잡도에 맞추기가 지극히 어려울 것 같은 2-layer 퍼셉트론 같은 임의의 분류 기법들과 함께 사용될수 있다는 것이다.



댓글