2020-2학기 서강대 김경환 교수님 강의 내용 및 패턴인식 교재를 바탕으로 본 글을 작성하였습니다.
4.3 Nonparametric techniques - Parzen Windows
▶ The Parzen-window approach to estimating densities
밀도를 추정하기 위한 Parzen-window 방식은 임시적으로 영역 $R_n$이 $d$-dimensional hypercube라고 가정해서 소개될 수 있다. 만일 $h_n$이 hypercube의 한 변의 길이라면, 그 부피는 다음과 같다.
$$V_n = h_n^{d} \tag{1}\label{eq1}$$
▶ Window function
다음의 window function "식 (2)"을 정의해서 hypercube(초육면체)에 있는 샘플 수 $k_n$에 대한 해석학적으로 표현을 얻을 수 있다.
$$
\varphi(\mathbf{u})=\left\{\begin{array}{ll}
1 & \left|u_{j}\right| \leq 1 / 2 \quad j=1, \ldots, d \\
0 & \text { otherwise }
\end{array}\right. \tag{2}\label{eq2}
$$
따라서 $\varphi(\mathbf{u})$는 원점을 중심으로 하는 단위 초육면체를 정의한다. 만일 $\mathbf{x}_i$가 $\mathbf{x}_i$를 중심으로 하는 부피 $V_n$의 초육면체의 안에 포함되면, $\varphi((\mathbf{x}-\mathbf{x}_i)/h_n)$은 1이며, 그렇지 않으면 0이다. 그러므로 이 초육면체에 있는 샘플 수는 식 (3)과 같다.
▶ The number of samples in the hypercube is
$$
k_{n}=\sum_{i=1}^{n} \varphi\left(\frac{\mathbf{x}-\mathbf{x}_{i}}{\hbar_{n}}\right) \tag{3}\label{eq3}
$$
이를 4.7 Nonparametric techniques - Density Estimation의 식 (7)에 대입할 때 다음의 추정을 얻는다.
$$
p(\mathbf{x}_n) \cong \frac{k_n / n}{V_n}
$$
위 식의 $k_n$에 식 (3)을 대입하면 다음과 같음
▶ and the estimate becomes
$$
p_{n}(\mathbf{x})=\frac{1}{n} \sum_{i=1}^{n} \frac{1}{V_{n}} \varphi\left(\frac{\mathbf{x}-\mathbf{x}_{i}}{h_{n}}\right) \tag{4}\label{eq4}
$$
이 식은 밀도 함수들을 추정하려는 일반적인 방식이다. 식 (4)는 $p_{n}(\mathbf{x})$에 대한 우리의 추정을 $\mathbf{x}$와 샘플 $\mathbf{x}_i$의 함수들의 평균으로 표현하고 있다. 근본적으로 window function는 interpolation(보간법, 각 샘플이 $\mathbf{x}$로부터의 거리에 따라서 추정에 기여하는)을 위해 사용될 것이다.
함수의 성질에 따라서 $p_n(\mathbf{x})$는 음수가 아니여야 하는 것과 적분하면 1이 되어야 하는 것은 당연하다. 이것은 window function 자체가 밀도 함수이어야 함을 요구하면 보장될 수 있다.
$$\varphi(\mathbf{x}) \ge 0 \tag{5}\label{eq5}$$
그리고
$$
\int \varphi(\mathbf{u}) d \mathbf{u}=1 \tag{6}\label{eq6}
$$
을 요구하고 관계 $V_n = h_n^{d}$를 유지한다면, 동시에 $P_n(\mathbf{x})$도 이 조건들을 만족시키게 된다.
▶ The effect of the window width $h_n$ on $p_n(\mathbf{x})$
$p_n(\mathbf{x})$에 대한 window width $h_n$의 효과를 조사해 보자. 함수 $\varphi(\mathbf{x})$를
$$
\delta_{n}(\mathbf{x})=\frac{1}{V_{n}} \varphi\left(\frac{\mathbf{x}}{h_{n}}\right) \tag{7}\label{eq7}
$$
으로 정리하면, $p_n(\mathbf{x})$를 평균인
$$
p_{n}(\mathbf{x})=\frac{1}{n} \sum_{i=1}^{n} \delta_{n}\left(\mathbf{x}-\mathbf{x}_{i}\right) \tag{8}\label{eq8}
$$
으로 쓸 수 있다. $V_n = h_n^{d} $이므로, $h_n$은 분명히 $\delta_n{\mathbf{x}}$의 진폭과 폭에 영향을 미친다. (그림 4.3)
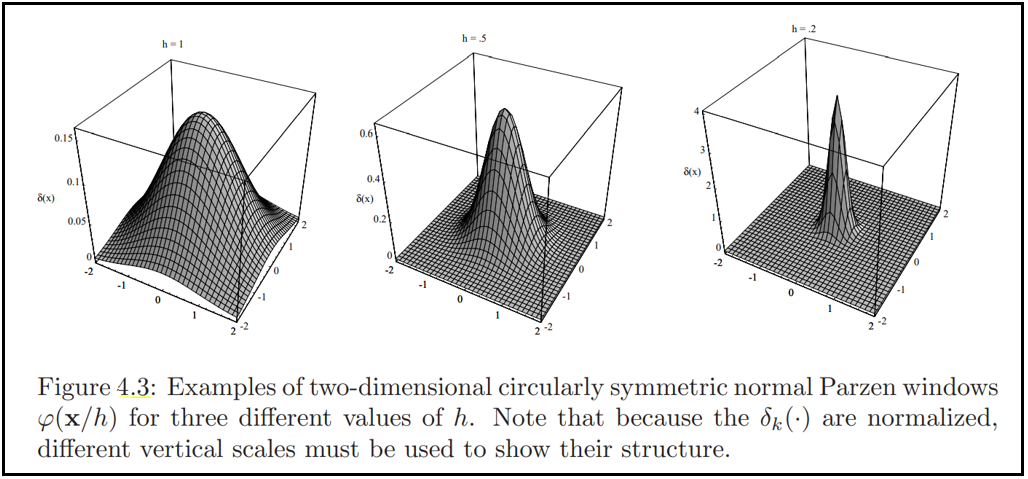
- 만일 $h_n$이 매우 크다면, $\delta_n$의 진폭은 작고, $\delta_n(\mathbf{x}-\mathbf{x}_i)$가 $\delta_n(\mathbf{0})$으로부터 많이 변하기 전에 $\mathbf{x}$는 $\mathbf{x}_i$로부터 멀리 있어야 함. 이 경우, $p_n(\mathbf{x})$는 n개의 매우 넓고, 천천히 변하는 함수들의 중첩이며 $p(\mathbf{x})$에 대한 매우 부드러운 "초점이 맞지 않은(out of focus)" 추정이다.
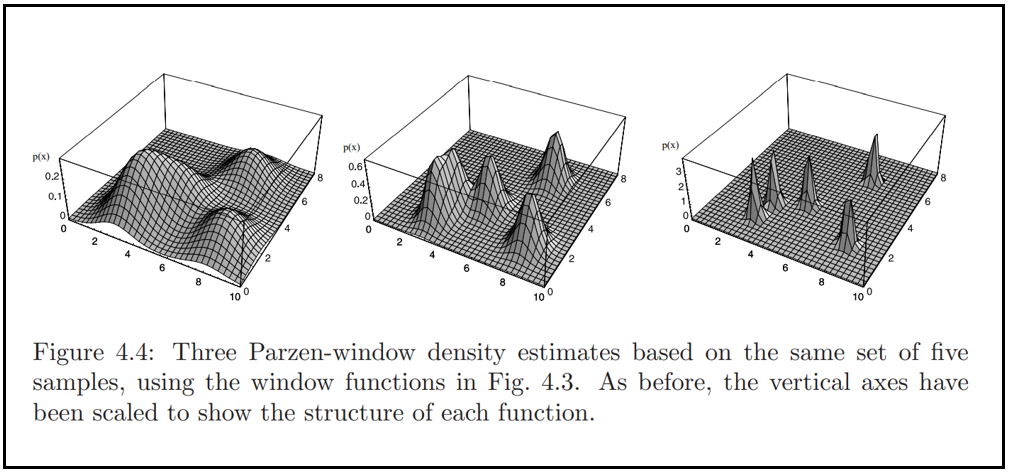
- 반면, 만일 $h_n$이 매우 작다면 $\delta(\mathbf{x}-\mathbf{x}_i)$의 피크값은 크며, $\mathbf{x} = \mathbf{x}_i$ 근처에서 발생한다. 이 경우 $p(\mathbf{x})$는 샘플들에 중심하는 $n$개의 날카로운 펄스의 중첩(superposition, 산만한 "노이즈" 추정)이다. (그림 4.4)
$h_n$의 어떠한 값에 대해서든, 분포는 정규화된다. 즉,
$$
\int \delta_{n}\left(\mathbf{x}-\mathbf{x}_{i}\right) d \mathbf{x}=\int \frac{1}{V_{n}} \varphi\left(\frac{\mathbf{x}-\mathbf{x}_{i}}{h_{n}}\right) d \mathbf{x}=\int \varphi(\mathbf{u}) d \mathbf{u}=1 \tag{9}\label{eq9}
$$
이다. 따라서 $h_n$이 어떠한 값에 따라 $\delta(\mathbf{x}-\mathbf{x}_i)$는 $\mathbf{x}_i$에 중심하는 Dirac 델타 함수에 접근하며, $p_n(\mathbf{x})$는 샘플들에 중심하는 델타 함수들의 중첩에 접근하다.
▶ The choice of $h_n$(or $V_n$) has an important effect on $p_n(\mathbf{x})$
분명히, $h_n$(또는 $V_n$)의 선택은 $p_n(\mathbf{x})$에 중요한 영향을 미친다.
- $V_n$이 너무 크다면, 추정의 해상도가 너무 낮아짐
- $V_n$이 너무 작다면, 추정의 통계적 변동성(statistical variability)이 너무 커짐 (그림 4.4)
제한된 샘플 수로 할 수 있는 최선은 "어떤 수용할만한 타협점"을 찾는 것이다. 하지만, 제한 없는 샘플 수로는 $n$이 증가함에 따라 $V_n$이 서서히 0에 접근하게 하고 $p_n(\mathbf{x})$가 미지의 밀도 $p(\mathbf{x})$에 수렴하게 하는 게 가능하다.
▶ Convergence
$p_n(\mathbf{x})$는 어떤 평균 $\bar{p}_{n} (\mathbf{x})$와 분산 $\sigma^2_n{\mathbf{x}}$를 갖는다. 다음과 같을 때 추정 $p_n{\mathbf{x}}$가 $p(\mathbf{x})$에 수렴한다고 말한다.
$$
\lim _{n \rightarrow \infty} \bar{p}_{n}(\mathbf{x})=p(\mathbf{x}) \tag{10}\label{eq10}
$$
그리고
$$
\lim _{n \rightarrow \infty} \sigma_{n}^{2}(\mathbf{x})=0 \tag{11}\label{eq11}
$$
▶ Conditions needed to prove convergence
수렴성을 증명하기 위해 미지의 밀도 $p(\mathbf{x})$, window function $\varphi(\mathbf{u})$, window height $h_n$에 관한 조건을 두어야 한다. 일반적으로 $\mathbf{x}$에서 $p(\cdot)$의 연속성이 요구되며, 아래 식 2개에 의해 부과된 조건들이 관례적으로 불려온다.
$$
\begin{array}{c}
\varphi(\mathbf{x}) \geq 0 \\ \\
\int \varphi(\mathbf{u}) d \mathbf{u}=1
\end{array}
$$
아래에서는 다음의 추가조건들이 수렴성을 보장함을 보인다.
$$
\begin{array}{c}
\sup _{\mathbf{u}} \varphi(\mathbf{u})<\infty \tag{12}\label{eq12}
\end{array}
$$
$$
\begin{array}{c}
\lim _{\|\mathbf{u}\| \rightarrow \infty} \varphi(\mathbf{u}) \prod_{i=1}^{d} u_{i}=0 \tag{13}\label{eq13}
\end{array}
$$
식 (12)와 (13)은 $\varphi(\cdot)$를 다루기 좋게 유지하며, 윈도우 함수로서의 사용이 고려될 수 있는 대부분의밀도 함수들에 의해 만족된다.
$$
\lim _{n \rightarrow \infty} V_{n}=0 \tag{14}\label{eq14}
$$
$$
\lim _{n \rightarrow \infty} n V_{n}=\infty \tag{15}\label{eq15}
$$
식 (14)와 (15)는 부피 $V_n$이 0에 접근해야 하나, 그 속도는 $1/n$보다 느려야 함을 말한다. 이제 왜 이들이 수렴을 위한 기본 조건들인지를 확인해보자.
▶ Convergence of the Mean
우선, $p_n(\mathbf{x})$의 평균인 $\bar{p}_{n}(\mathbf{x})$를 고려하자. 샘플 $\mathbf{x}_i$가 (미지) 밀도 $p(\mathbf{x})$에 따른 $i.i.d$ 이므로,
$$
\begin{aligned}
\bar{p}_{n}(\mathbf{x}) &=\mathcal{E}\left[p_{n}(\mathbf{x})\right] \\
&=\frac{1}{n} \sum_{i=1}^{n} \mathcal{E}\left[\frac{1}{V_{n}} \varphi\left(\frac{\mathbf{x}-\mathbf{x}_{i}}{h_{n}}\right)\right] \\
&=\int \frac{1}{V_{n}} \varphi\left(\frac{\mathbf{x}-\mathbf{v}}{h_{n}}\right) p(\mathbf{v}) d \mathbf{v} \\
&=\int \delta_{n}(\mathbf{x}-\mathbf{v}) p(\mathbf{v}) d \mathbf{v}
\end{aligned} \tag{16}\label{eq16}
$$
이다.
convolution ?? 확인 필요
▶ Convergence of the Variance
식 (16)은 $\bar{p}_{n}(\mathbf{x})$가 $\p(\mathbf{x})$에 접근하게 만들기 위해 무한개의 샘플이 필요하지 않음을 보여준다. (어떤 $n$에 대해서든 단지 $V_n$이 0에 접근하게 해서 이를 달성할 수 있음). 물론 $n$개의 샘플의 어떤 특정 집합에 대해서는 결과로 얻은 "뾰족한" 추정이 필요 없다. 이 사실은 우리가 추정의 분산을 고려할 필요성을 강조한다. $p_n(\mathbf{x})$가 통계적으로 독립적인 랜덤 변수들의 함수들의 합이므로, 그 분산은 분리된 항들의 분산들의 합이고, 따라서
$$
\begin{aligned}
\sigma_{n}^{2}(\mathbf{x}) &=\sum_{i=1}^{n} \mathcal{E}\left[\left(\frac{1}{n V_{n}} \varphi\left(\frac{\mathbf{x}-\mathbf{x}_{i}}{h_{n}}-\frac{1}{n} \bar{p}_{n}(\mathbf{x})\right)\right)^{2}\right] \\
&=n \mathcal{E}\left[\frac{1}{n^{2} V_{n}^{2}} \varphi^{2}\left(\frac{\mathbf{x}-\mathbf{x}_{i}}{h_{n}}\right)\right]-\frac{1}{n} \bar{p}_{n}^{2}(\mathbf{x}) \\
&=\frac{1}{n V_{n}} \int \frac{1}{V_{n}} \varphi^{2}\left(\frac{\mathbf{x}-\mathbf{v}}{h_{n}}\right) p(\mathbf{v}) d \mathbf{v}-\frac{1}{n} \bar{p}_{n}^{2}(\mathbf{x})
\end{aligned} \tag{17}\label{eq17}
$$
이다. 두 번째 항을 버리고 $\varphi(\cdot)$ 제한하고, 식 (23)을 이용해서 다음을 얻을 수 있다.
$$
\sigma_{n}^{2}(\mathbf{x}) \leq \frac{\sup (\varphi(\cdot)) \bar{p}_{n}(\mathbf{x})}{n V_{n}} \tag{18}\label{eq18}
$$
작은 분산을 얻기 위해서는 분모에 있는 작은 $V_n$이 아닌 큰 $V_n$을 요구할 것이다. 그러나 큰 $n$이 무한대에 접근해도 분자는 유한하므로, $n V_n$이 무한대로 접근하다고 가정하면, $V_n$이 0에 접근하게 하고도 분산이 0임을 얻을 수 있다.
예를 들면 아래와 같은 식 또는 식 (14), (15)를 만족시키는 어떤 함수든 분산을 0으로 만들 수 있다.
- $V_n = V_1 / \sqrt{n}$
- $V_n = V_1 / \ln {n}$
▶ Illustration (보기)
Parzen-window 기법이 단순한 예제들에 대해 어떻게 적용하는지를 확인하는 것, 그리고 특히 window function의 효과를 확인해보자. 우선 $p(\mathbf{x})$의 zero-mean(평균:0), unit-variance (분산:1)인 단변량 노말 밀도인 경우를 고려하자. window-function은 다음과 같은 형태라고 하자.
$$
\varphi(u)=\frac{1}{\sqrt{2 \pi}} e^{-u^{2} / 2} \tag{19}\label{eq119}
$$
끝으로, $h_n = h_1 / \sqrt{n}$ 이라고 하자. 여기서 $h_1$은 임의로 처리할 수 있는 parameter이다. 따라서 $p(x)$는 샘플들에 중심하는 노멀 밀도들의 평균이다.
$$
p_{n}(x)=\frac{1}{n} \sum_{i=1}^{n} \frac{1}{h_{n}} \varphi\left(\frac{x-x_{i}}{h_{n}}\right) \tag{20}\label{eq20}
$$
$p_n(x)$의 평균과 분산을 찾아내기 위해 식 (16), (17)을 계산하는 것은 어렵지 않으나, 수치적 결과를 아래 그림으로 확인해보자.
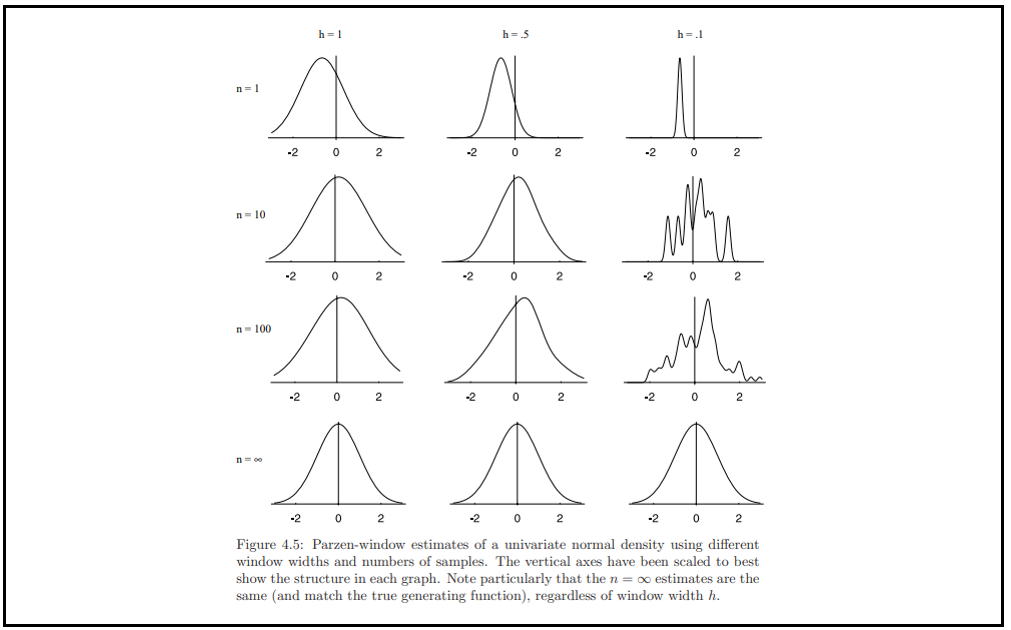
... 설명 추가!
bivariate normal
bimodal distribution
▶ Classification Example (분류 예제)

Reference
'Pattern Classification [수업]' 카테고리의 다른 글
| Ch5.2 Linear Discriminant Functions - Linear Discriminant Functions and Decision Surfaces (0) | 2020.10.29 |
|---|---|
| Ch5.1 Linear Discriminant Functions - Introduction (0) | 2020.10.29 |
| Ch4.2 Nonparametric techniques - Density Estimation (0) | 2020.10.07 |
| Ch4.1 Nonparametric techniques - Introduction (0) | 2020.10.07 |
| Ch3.3~4 Bayes Estimation [The univariate case] (0) | 2020.09.25 |


댓글