2020-2학기 서강대 김경환 교수님 강의 내용 및 패턴인식 교재를 바탕으로 본 글을 작성하였습니다.
앞선 Ch3 에서는 미지의 확률 밀도 함수를 추정하기 위해 model (분포)을 가정하고 접근하였지만, Ch4 는 model 을 모른다는 가정이 덜 들어감으로써 치룰 "대가"가 있다. (예를 들면, 추정 하기 위해 data가 훨씬 더 많이 필요로 함)
4.2 Nonparametric techniques - Density Estimation
▶ Estimating an unknown probability density function
비록 추정들이 수렴하는 정밀한 데모들은 많은 주의를 요구하지만, 미지의 확률 밀도 함수를 추정하는 방법 중 대다수의 배경이 되는 기본 아이디어들은 매우 단순하다. 가장 근본적인 기법은 벡터 $\mathbf{x}$가 영역 $R$에 들 확률 $P$가 다음식에 의해 주어진다는 사실에 의존한다. (아래 설명)
- The probability $P$ that a vector $\mathbf{x}$ will fall in a region $R$ is given by
$$
P=\int_{R} p\left(\mathbf{x}^{\prime}\right) d \mathbf{x}^{\prime} \tag{1}\label{eq1}
$$
- $P$ is an averaged version of the density function $p(\mathbf{x})$.
$P$는 밀도 함수 $p(\mathbf{x})$의 부드럽게 되거나 평균화된 버전이다.
- Smoothed value of $p$ can be estimated by estimating the $P$.
우리는 $P$를 추정해서 이 부드럽게 된 $p$의 값을 추정할 수 있다.
- Supposed that $\mathbf{x}_1, ... , \mathbf{x}_n$ are drawn i.i.d. according to the probability law $P(\mathbf{x})$. The probability that $k$ of these $n$ fall in $R$ is given by the binomial law.
n개의 샘플 $\mathbf{x}_1, ... , \mathbf{x}_n$이 확률 법칙 $p(\mathbf{x})$에 따라 독립적이고 동일하게 분포(i.i.d)되도록 뽑힌다고 하면, 이 $n$개 중 $k$개가 $R$에 포함될 확률은 이항 법칙에 의해 다음과 같이 주어진다.
$$
P_{k}=\left(\begin{array}{l}
n \\
k
\end{array}\right) P^{k}(1-P)^{n-k} \tag{2}\label{eq2}
$$
그리고 $k$에 대한 이론적으로 기대값은
$$E[k] = nP \tag{3}\label{eq3}$$
이다
- This binomial distribution peaks very sharply about the mean. (1,2 내용)
- The ratio $k/n$ will be a very good estimate for the $P$.
- This estimate is accurate when $n$ is very large.
$k$에 대한 이 이항 분포는 평균을 중심으로 매우 날카로운 피크를 만든다. $k/n$는 $P$에 대한 좋은 추정값이 될 것이며, 이 추정은 샘플 $n$이 매우 클 때 특히 정확하다.
- If $p(\mathbf{x})$ is continuous and $R$ is so small that $p$ does not vary appreciably within it
$$
\int_{R} p\left(\mathbf{x}^{\prime}\right) d \mathbf{x}^{\prime} \cong p(\mathbf{x}) V \tag{4}\label{eq4}
$$
where $\mathbf{x}$ is a point within $R$ and and $V$ is the volume enclosed by $R$.
만일 $p(\mathbf{x})$는 연속적이며, 영역 $R$이 너무 작아서 $p$가 그 안에서 감지될 수 있을 만큼 변하지 않는다고 가정한다면, 식 (4)와 같이 쓸 수 있다. 여기서 $\mathbf{x}$는 $R$ 내부의 점이며 $V$는 $R$에 의해 둘러싸인 부피다. 식 (1), (3), (4)를 결합하면, 그림 [4.1]에 보인과 같이. $p(\mathbf{x})$에 대한 다음의 분명한 추정에 도달한다.
$$
p(\mathbf{x}) \cong \frac{k / n}{V} \tag{5}\label{eq5}
$$
지금까지 $p(\mathbf{x})$를 추정하기 위한 절차를 간단히 정리하면 다음과 같다.

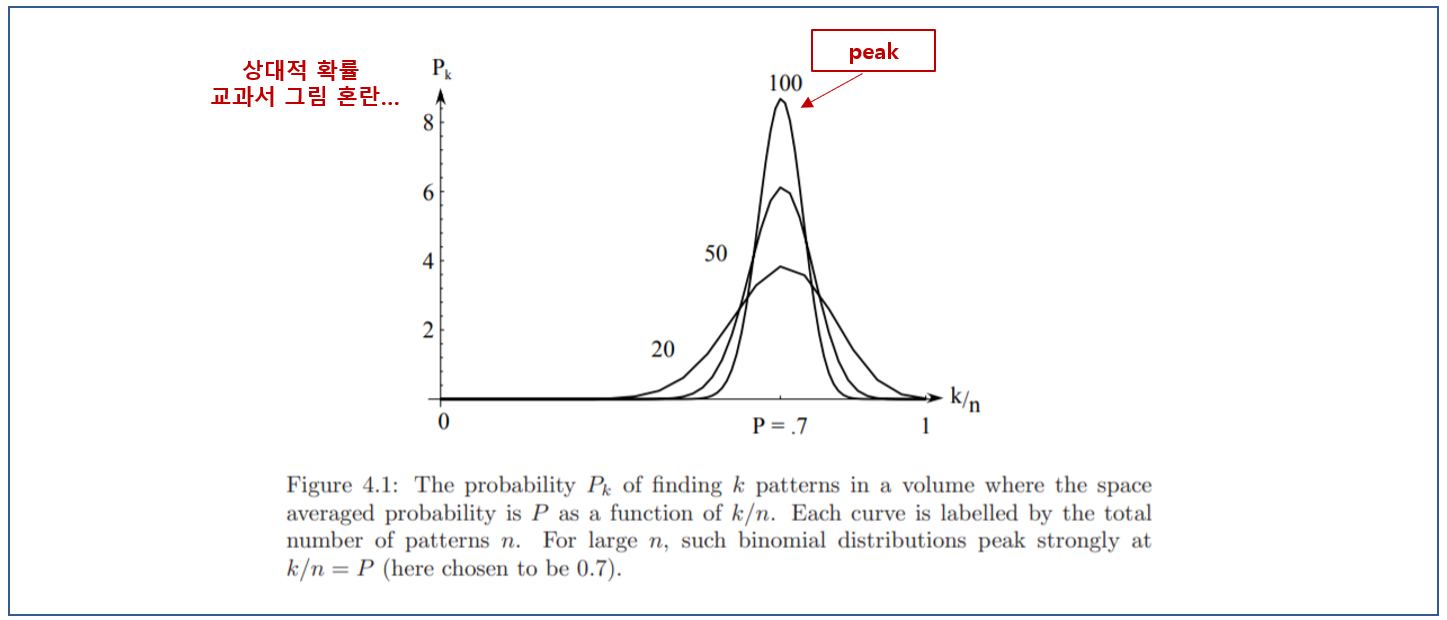
아직 남아있는 몇 가지 문제가 있는데 천천히 살펴보도록 하자.
- Problems remaining : Practical / Theoretical
- If we fix $V$ and take more and more training samples, $k/n$ will converge, but then we have only obtained an estimate of the space-averaged value of $p(\mathbf{x})$.
$$
\frac{P}{V}=\frac{\int_{R} p\left(\mathbf{x}^{\prime}\right) d \mathbf{x}^{\prime}}{\int_{R} d \mathbf{x}^{\prime}} \tag{6}\label{eq6}
$$
만일 부피 $V$를 고정시키고 점점 더 많은 훈련 샘플 $n$을 취한다면, $k/n$ 비는 바라는 대로 수렴(확률적으로)할 것이다. 그러면 $p(\mathbf{x})$의 공간-평균화 값의 추정을 식 (6)얻게 될 뿐이다. 만일 평균화된 버전이 아닌 $p(\mathbf{x})$를 얻기를 원한다면, $V$가 $0$에 접근하는 데 대비해야 한다. 그러나 샘플 $n$을 고정시키고 $V$가 $0$에 접근하게 만들면, 영역은 궁긍적으로 매우 작아져서 아무 샘플도 둘러싸지 않을 것이며, 추정 $p(\mathbf{x}) \simeq 0$은 쓸모없게 될 것이다. 또는 우연히 하나 이상의 훈련 샘플이 $\mathbf{x}$에서 동시에 발생하면, 추정은 무한대로 발산하며, 이것 또한 마찬가지로 무용하다.
- From a practical standpoint : 실용적 관점
we note that the number of samples is always limited. Thus $V$ cannot be allowed to become arbitrarily small. If this kind of estimate is to be used, one will have to accept a certain amount of variance in the $k/n$ and a certain amount of averaging of the density $p(\mathbf{x})$.
현실에서는 샘플 수가 항상 제한됨을 유념하자. 따라서 부피 $V$가 임의 크기로 작아지게 혀용할 수는 없다. 그럼에도 불구하고 위의 방법으로 추정하려면 $k/n$ 비의 일정 양의 분산과 밀도 $p(\mathbf{x})$의 일정 양의 평균화를 받아들어야만 한다.
- From a theoretical standpoint : 이론적 관점
It is interesting to ask how these limitations can be circumvented if an unlimited number of samples is available. Let $V_n$ be the volume of $R_n$, $k_n$ be the number of samples falling in $R_n$, and $p_n(\mathbf{x})$ be the $n$-th estimate for $p(\mathbf{x})$:
이론적 관점에서는, 제한되지 않은 수의 샘플들이 가용하다면, 이 제한들이 어떻게 해결되는지 흥미로운 일이다. $p(\mathbf{x})$에서의 밀도를 추정하기 위해서, $\mathbf{x}$를 포함하는 일련의 영역 $R_1, R_2, ... $을 형성한다. - 첫 번째 영역은 하나의 샘플, 두 번째는 둘... , 그리고 $V_n$은 $R_n$의 부피, $k_n$은 $R_n$에 포함될 샘플 수, $p_n(\mathbf{x})$는 $p(\mathbf{x})$에 대한 $n$번째 추정이라고 하자 :
$$
p_{n}(\mathbf{x})=\frac{k_{n} / n}{V_{n}} \tag{7}\label{eq7}
$$
If $p_n(\mathbf{x})$ is to be converge to $p(\mathbf{x})$, following conditions appear to be required
만일 $p_n(\mathbf{x})$가 $p(\mathbf{x})$에 수렴하려면, 세 조건이 요구될 것이다.

첫번째 조건 : 영역들이 균일하게 축소되고, $p(\codt)$이 $\mathbf{x}$에서 연속적이라고 할때, 공간 평균화된 $P/V$가 $p(\mathbf{x})$에 수렴할 것임을 보장해야 함.
두번째 조건 : $p(\mathbf{x}) \neq 0$일 때만 성립하는데, 빈도 비가(확률적으로) 확률 $P$에 수렴할 것임을 보장해야 함
세번째 조건 : 식 (7)에 의해 주어진 $p_n(\mathbf{x})$가 수렴하려면 분명히 필요하다. 이것은 또한 큰 수의 샘플들이 궁긍적으로 작은 영역 $R_n$에 놓일 것이지만, 전체 샘플 수에서 무시할 수 있을 정도로 작은 부분을 구성할 것임을 말해준다.
- Two common ways of obtaining sequences of regions that satisfy these conditions.
위 조건들을 만족시키는 영역들의 시퀀스를 얻는 두 가지 보편적인 방법이 있다.

The sequences in both cases represent random variables that generally converge and allow the true density at the test point to be calculated.
두 경우 모두 시퀀스는, 일반적으로 수렴하고 테스트 점에서의 True 밀도가 계산되게 허용하는 랜덤 변수들을 나타낸다.
다음 Ch4.2에서는 "Nonparametric techniques - Density Estimation"에서 "Parzen-window" 추정 방법을 보다 자세히 살펴볼 예정입니다.
Reference
'Pattern Classification [수업]' 카테고리의 다른 글
| Ch5.1 Linear Discriminant Functions - Introduction (0) | 2020.10.29 |
|---|---|
| Ch4.3 Nonparametric techniques - Parzen Windows (0) | 2020.10.12 |
| Ch4.1 Nonparametric techniques - Introduction (0) | 2020.10.07 |
| Ch3.3~4 Bayes Estimation [The univariate case] (0) | 2020.09.25 |
| Ch3.2 Maximum-likelihood Estimation (0) | 2020.09.22 |


댓글