본 포스팅은 모두의연구소(home.modulabs.co.kr) [풀잎스쿨 15기] 에서 진행된 'Semantic Segmentation 논문으로 입문하기' 과정 내용을 공유 및 정리한 자료입니다.

Contents
- Introduction
- Related Work
- Proposed Network Architecture: UNet++
- Experiments
- Conclusion
Keywords
- Medical Image Segmentation
Introduction
- Image segmentation에서 SOTA(최신 모델)는 U-Net, FCN처럼 the encoder-decoder 아키텍처의 변형
- U-net, FCN 모델들의 성능이 좋았던 이유는 아래 그림에서의 구조에서 표시된, 즉, 노랑 타원형으로 강조된 "skip connections" 때문

즉, skip connection을 이용하면, 하위 decoder에서 output(label)의 세부 정보를 복구하는데 효과적임을 입증되었다.
- 일반 사물들을 대상으로 분류하는 Mask-RCNN model에서도 "skip connection"을 사용하여 좋은 성능을 달성했다. 하지만, 의료 이미지처럼 엄격한 데이터를 segmentation 하는데 있어서 요구사항을 충족할지 의문을 남김
- 의료 영상에서 Segmenting lesions 또는 abnormalities를 분할하려면, 기존 모델 대비(e.g. U-net)하여 높은 수준의 정확도를 필요로 함
- 높은 정확도를 얻기 위해, 이 논문에서는 a new segmentation architecture based on nested and desne skip connection 의 U-net++를 제안하게 되었다.
논문에서는 구조에 대한 기본적인 가설을 다음과 같이 정의하고 있다.
- Encoder 네트워크의 고해상도 feature map이 Decoder 네트워크의 해당 의미가 풍부한 feature map과 융합되기 전에 점진적으로 강화 될 때 모델이 전경 객체의 세밀한 세부 사항을보다 효과적으로 캡처 할 수 있다는 것
- Decoder및 Encoder 네트워크의 feature map 이 semantically similar 라면, 네트워크가 더 쉬운 학습 작업을 처리 할 것 (이 부분이 Unet과 다른 네트워크 구조 차이점)
즉, 논문 저자가 진행한 실험에 따르면, U-net++가 U-net 및 wide U-net보다 상당한 성능 향상을 가져온다고 한다.
Related Work
- Fully convolution networks / U-Net 의 key idea는 skip connections
- FCN :

- U-Net :

- H-denseunet : Liver와 Tumor Segmentation을 위한 새로운 네트워크 H-DenseUNet을 제안한 논문

| Despite the minor differences between the above architectures, they all tend to fuse semantically dissimilar feature maps from the encoder and decoder sub-networks, which, according to our experiments, can degrade segmentation performance |
위에서 제안된 여러 구조의 사소한 차이에도 불구하고 모두 encoder 및 decoder에서 얻어진 feature map을 네트워크의 의미상 유사하지 않은 feature map을 연결하는 경향이 있지만, 실험에 따르면 segmenation의 성능을 저하시킬 수 있다고 한다. (확인 필요)
- GridNet : an encoder-decoder architecture wherein the feature maps are wired in a grid fashion, generalizing several classical segmentation architectures. however, lacks up-sampling layers between skip connections; and thus, it does not represent UNet++.
- Mask-RCNN : Mask-RCNN is perhaps the most important meta framework for object detection, classification and segmentation.
저자는 논문에 mask-RCNN의 구조를 backbone 사용한 U-Net++(with nested dense skip pathways)의 실험 결과를 넣고 싶었으나, 논문 페이지 제약으로 인해, 보충 자료에 첨부했다고 함
Proposed Network Architecture : UNet++

- U-Net++ consists of an encoder and decoder that are connected through a series of nested dense convolutional blocks.
- The main idea behind U-Net++ is to bridge the semantic gap between the feature maps of the encoder and decoder prior to fusion.
- In the graphical abstract, black indicates the original U-Net, green and blue show dense convolution blocks on the skip pathways, and red indicates deep supervision.
[Figure 6]에서 구조를 보면, Unet++은 an encoder sub-network(or backbone)으로 시작해서, a decoder sub-network로 끝나게 된다. (이 black 색으로 표현된 U자형 구조는 기존 Unet과 동일함) 하지만, Unet++에서는 U자형 구조 안안에 있는 skip-connection (skip pathways : green / blue)의 방법과 deep supervision (red)이 재설계되었음을 알 수 있다.
▶ 3.1 Re-designed skip pathways
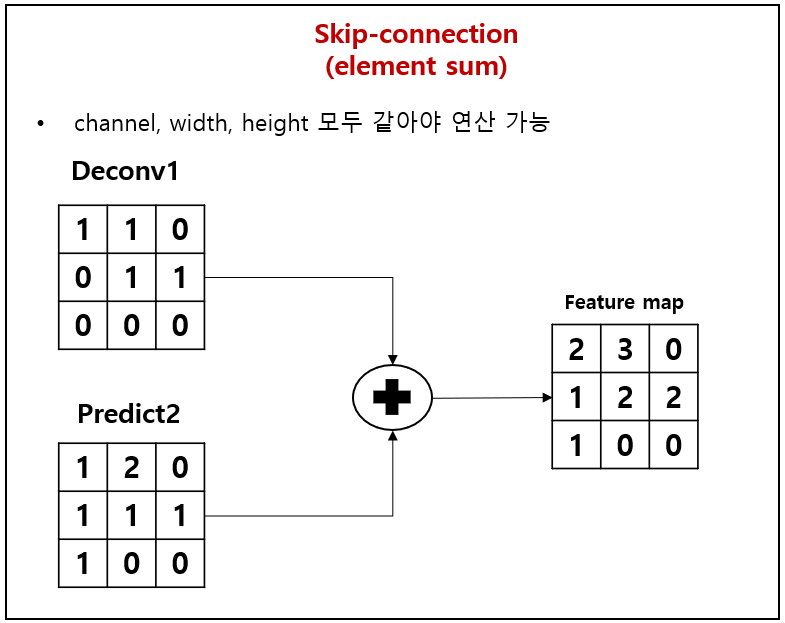
- 재설계된 skip pathway는 encoder 및 decoder 하위 네트워크의 연결을 변환
- 기존, U-net에서는 encoder의 feature map들이 각각 decoder에 직접 skip-connection 되었음
- 하지만, U-net++에서는 encoder의 feature map들이 [Figure 6]의 pyramid level에 따라 달라지는 convolution layer들의 수를 가지는 dense convolution block을 통과
- $i$ : indexes the down-sampling layer along the encoder
- $j$ : indexes the convolution layer of the dense block along the skip pathway
Example :
- $\bf{X}^{0,0}$ : Convolution (e.g. $i$ : 0 , $j$ : 0)
- $\bf{X}^{1,3}$ : Convolution (e.g. $i$ : 1 , $j$ : 3)

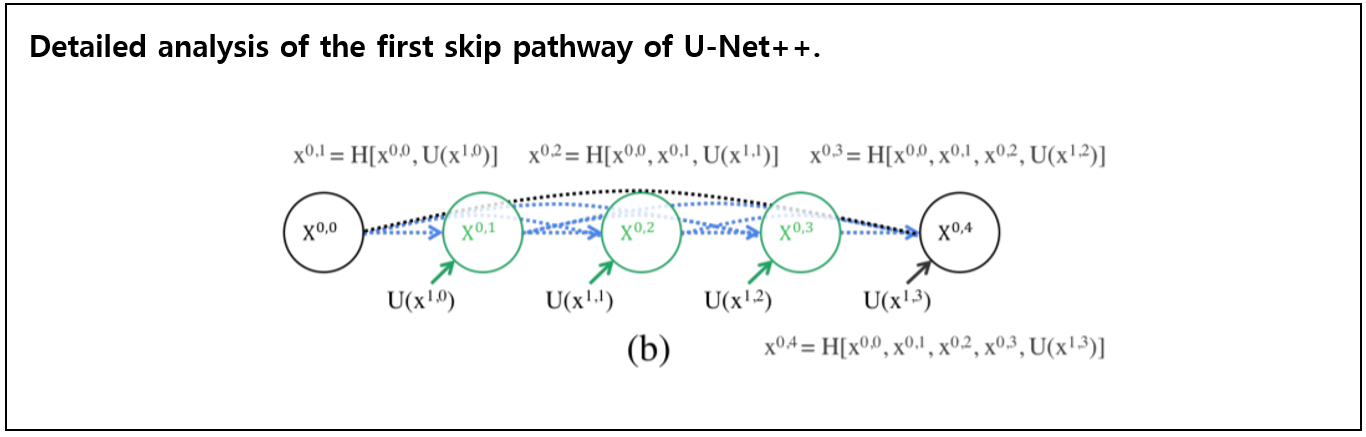
[Figure7]에서 $\bf{X}^{0,0}$ 노드 (purple circle) 와 $\bf{X}^{1,3}$ 노드 (purple circle) 사이에는 skip pathway (same dense block, blue box)가 있다. skip pathway안에는 3개의 convolution Layer($\bf{X}^{1,0}$, $\bf{X}^{1,1}$, $\bf{X}^{1,2}$)가 존재한다. 이 각각의 convolution layer는 같은 level에 존재하는 dense block의 이전 시점의 convolution layer의 출력과 아래 존재하는(level이 다른) dense block의 up-sampling된 출력과 concat되어진 layer다. (e.g. $\bf{X}^{1,2}$의 layer는 동일한 dense block에 있는 앞의 layer인 $\bf{X}^{1,1}$과 하위 level의 dense block에 존재하는 $\bf{X}^{2,1}$와 concat된 결과 연결하는 layer를 의미함)
- 본질적으로 dense convolution block은 encoder feature map의 semantic level(의미)를 decoder에서 대기중인 feature map의 semantic level(표현력?)를 더 가깝게 만듬
- 가설 : decoder단에서 출력된 feature map과 encoder단에서 보내지는 feature map이 semantically simillar(의미적으로 유사)할 때 최적화하기 쉬울 것
Q&A (1): semantically simillar라는 표현이 모호하다. 가령, 수치적으로 값이 비슷하다고 봐도 괜찮은가? (그렇다면, 왜 비슷할 수 있는지, 수학 및 구조적으로 와닿지 않음)
Formally, we formulate the skip pathway as follows :
$$
x^{i, j}=\left\{\begin{array}{ll}
\mathcal{H}\left(x^{i-1, j}\right), & j=0 \\
\mathcal{H}\left(\left[\left[x^{i, k}\right]_{k=0}^{j-1}, \mathcal{U}\left(x^{i+1, j-1}\right)\right]\right), & j>0
\end{array}\right. \tag{1}\label{1}
$$
where
- $\mathcal{H}(\cdot)$ : convolution operation followed by an activation function
- $\mathcal{U}(\cdot)$ : an up-sampling layer.
- $[ ]$ : the concatenation layer.
- $\bf{X}^{l , 0}$ : receive only one input from the previous layer of the encode.
- nodes at level $j = 0$ receive only one input from the previous layer of the encoder
- nodes at level $j = 1$ receive two inputs, both from the encoder sub-network but at two consecutive levels
- nodes at level $j \gt 1$ receive $j + 1$ inputs, of which $j$ inputs are the outputs of the previous $j$ nodes in the same skip pathway and the last input is the up-sampled output from the lower skip pathway.
모든 이전 feature map이 누적되어 현재 노드에 도착하는 이유는 각 스킵 경로를 따라 dense convolution block을 사용하기 때문!
▶ 3.2 Deep supervision
- U-net++에서는 deep supervision을 사용하여 모델이 두 가지 mode로 작동할 수 있도록 함
- accurate mode wherein the outputs from all segmentation branches are averaged
- fast mode wherein the final segmentation map is selected from only one of the segmentation branches, the choice of which determines the extent of model pruning and speed gain.
- the nested skip pathway 으로 인해, U-net++는 다양한 level(e.g. {$x^{0,j}, j \in \{1,2,3,4\}$})에서 full resolution feature map을 생성
- We have added a combination of binary cross-entropy and dice coefficient as the loss function to each of the above four semantic levels, which is described as:
$$
\mathcal{L}(Y, \hat{Y})=-\frac{1}{N} \sum_{b=1}^{N}\left(\frac{1}{2} \cdot Y_{b} \cdot \log \hat{Y}_{b}+\frac{2 \cdot Y_{b} \cdot \hat{Y}_{b}}{Y_{b}+\hat{Y}_{b}}\right) \tag{2}\label{2}
$$
where $\hat{Y}_b$ : the flatten predicted probabilities of $b^{th}$ image$, $\{Y}_b$ : the flatten ground truths of $b^{th}$ image, $N$ : the batch size
Q&A (2): 4개의 semantic levels에 각각 식 (2)로 정의하고 있다. 하나의 이미지의 ground truths 인 $\bf{Y}_b$가 각각 levels에 동일한 값으로 들어가는게 맞는지 확인 필요.
Q&A (3): 해당 논문에서의 실험 데이터 셋은 class가 0,1인 즉, binary 값을 분류하기 위해 binary cross-entropy를 사용한 것 같다. 만일, multi class를 분류하기 위해서는 cross-entopy를 사용하면 되는지 확인 필요. (loss function수정 필요로 함)
Proposed Network Architecture : UNet++를 요약함
- UNet++ differs from the original U-Net in three ways :
- having convolution layers on skip pathways (shown in green) which bridges the semantic gap between encoder and decoder feature maps
- having dense skip connections on skip pathways (shown in blue), which improves gradient flow
- having deep supervision (shown in red), which as will be shown in Section 4 enables model pruning and improves or in the worst case achieves comparable performance to using only one loss layer.
Experiments
Datasets : 아래 4개의 특징을 가지는 dataset에 대해 실험 진행, 더 디테일한 데이터셋 설명 및 전처리 과정은 보충 자료 (참고문헌) 등을 통해 알 수 있음
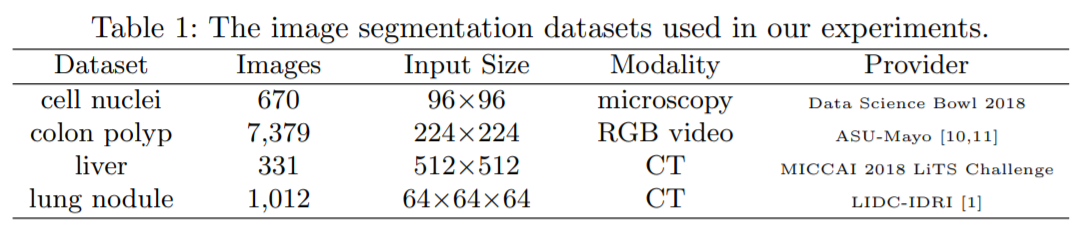
Baseline models : U-Net 및 U-Net의 구조를 조금 변형한 모델을 사용 (선정 이유 : image segmentation에서 일반적으로 좋은 성능을 보이고 있어서 채택), 그리고 parameter 수를 U-net과 비슷하게 설정하여 실험을 진행함 (performance를 측정하는데 있어서, parameter 갯수는 매우 중요한 조건)

Implementation details :
- We monitored the Dice coefficient and Intersection over Union (IoU).
- used early-stop mechanism on the validation set (overfitting 방지)
- Adam optimizer (lr = 3e-4)
- All convolution layers along a skip pathway ($\bf{X}^{i,j}) use $k$ kernels of size 3 x 3 (or 3 x 3 x 3 for 3D nodule segmentation)
- To enable deep supervision, a 1×1 convolutional layer followed by a sigmoid activation function was appended to each of the target nodes : $\{ x^{0,j} | j \in \{1,2,3,4\} \}$.
- 더 자세한 내용은 저자 코드를 확인하면 좋을것 같음 github.com/MrGiovanni/UNetPlusPlus
MrGiovanni/UNetPlusPlus
Official Keras Implementation for UNet++ in IEEE Transactions on Medical Imaging and DLMIA 2018 - MrGiovanni/UNetPlusPlus
github.com
Results :


- a multi-scale approach using all segmentation branches (deep supervision) is essential for accurate segmentation
Model pruning :

- More aggressive pruning further reduces the inference time but at the cost of significant accuracy degradation.
Conclusion
- To address the need for more accurate medical image segmentation, we proposed U-Net++.
- The suggested architecture takes advantage of re-designed skip pathways and deep supervision.
- The re-designed skip pathways aim at reducing the semantic gap between the feature maps of the encoder and decoder subnetworks, resulting in a possibly simpler optimization problem for the optimizer to solve
- Deep supervision also enables more accurate segmentation particularly for lesions that appear at multiple scales such as polyps in colonoscopy videos.
- We evaluated U-Net++ using four medical imaging datasets covering lung nodule segmentation, colon polyp segmentation, cell nuclei segmentation, and liver segmentation.
- Our experiments demonstrated that U-Net++ with deep supervision achieved an average IoU gain of 3.9 and 3.4 points over U-Net and wide U-Net, respectively.
References
- [UNet++: A Nested U-Net Architecture for Medical Image Segmentation](arxiv.org/pdf/1807.10165.pdf)
- [Unet++](medium.com/@codecompose/unet-480d378906fd
'Segmentation' 카테고리의 다른 글
| [Paper Review] MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS (2) | 2021.02.05 |
|---|

댓글