"action value"인 $Q_t(\alpha)$를 추정하고 이를 사용하여 행동을 결정하는 몇 가지 간단한 방법들을 살펴볼 것이다.
이 장에서는 행동 $\alpha$의 실제(true/actual value)값을 $q(\alpha)$로 표시하고 $t$번째 단계에서의 추정값은 $Q_t(\alpha)$로 표기한다.
한 가지 방법은 실제로 $t$시점 까지 받은 보상을 averaging(평균화)하는 것이다.
$$Q_t(\alpha) = \frac{\text{sum of rewrads when } \alpha \text{ taken prior to } t}{\text{number of times } \alpha \text{ taken prior to } t} = \frac{\sum_{i=1}^{t-1}R_i \cdot \mathbb{1}_{A_i = \alpha}}{\sum_{i=1}^{t-1} \mathbb{1}_{A_i = \alpha}}$$
처음에는 아무것도 안했기 때문에 기본 값 (default)을 0이며, 무한대로 갈 수록 the law of large numbers(대수의 법칙)에 의해, 이 값은 $q_(\alpha)$에 수렴할 것이다.
앞서 보상을 평균화하는 방법을 이용하여, $Q_t$ 값이 가장 큰 행동을 선택하는 것을"simple-average method for estimating action values"라고 부른다.
Greedy action
$$A_t = \underset{\alpha} {\mathrm argmax } Q_t(\alpha)$$
e.g : 위 식에 대한 원리는 python 코드로 설명을 하면 다음과 같다.
import numpy as np
array = np.array([1, 2, 5, 4, 3])
# 가장 큰 값을 가지는 element의 index 를 출력
print(np.argmax(array))1, 2, 5, 4, 3 값을 가진 array(list 또는 matrix)가 있다고 하면, 5가 가장 크기 때문에 5의 index인 2를 출력하게 된다.
"greedy action selection"은 항상 현재의 정보(지식)을 활용(exploits)하여 즉각적인 보상을 극대화합니다. 실제로 더 나은지 확인하기 위해 모든 샘플링에서 시간이 전혀 걸리지 않습니다. (단점, 탐험을 하지 않는다는 의미)
$\epsilon$ - Greedy action
보다 더 나은 방법인 "$\epsilon$ - Greedy action" 이 존재한다.
어떤 일정한 확률($\epsilon$)로 무작위 행동(random action, no-greedy)을 하고 나머지 확률($1-\epsilon$)은 "greedy action selection"을 하는 것.
e.g : 위 설명에 대한 원리는 python 코드로 설명을 하면 다음과 같다.
# epsilon greedy
eps = 0.1
p = np.random.random()
if p < eps:
print('p({}) < eps({})'.format(p, eps))
print('-------------------')
print('so, no-greedy action')
j = np.random.choice(len(array))
else:
print('p({}) >= eps({})'.format(p, eps))
print('-------------------')
print('so, greedy action')
j = np.argmax(array)
print('-------------------')
print('j = {}'.format(j))
print('-------------------')
x = array[j]
x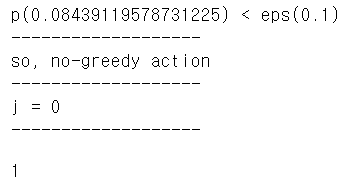 |
이렇게 $\epsilon$에 의해 자연스럽게 탐험(exploration)과 활용(exploitation)을 하게 된다. 무한히 진행을 한다면 $Q_{t}(\alpha)$가 q_(*}$로 수렴할 것이다. 하지만, 수렴했음에도 불구하고도 $\epsilon$에 의해 임의의 확률로 다른 행동을 하겠지만 이 방법이 greedy action 보다는 효과적이라고 한다.
Exercise 2.1 (위 e-greedy code) 참고
'Reinforcement Learning (d.silver)' 카테고리의 다른 글
| [강화학습] Lecture 2. Markov Decision Processes I (0) | 2021.03.30 |
|---|---|
| 2.3 The 10-armed Testbed (0) | 2020.07.24 |


댓글