- Intuition behind using win_type = "gaussian" with a rolling window
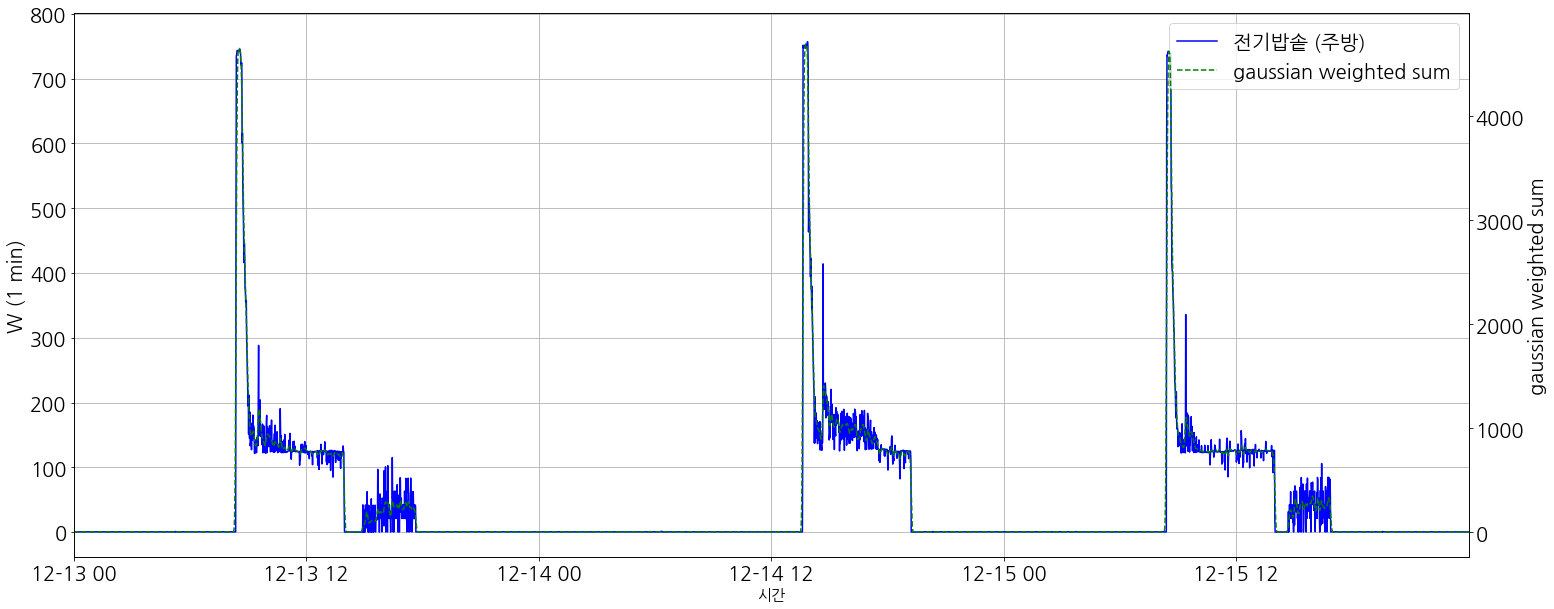
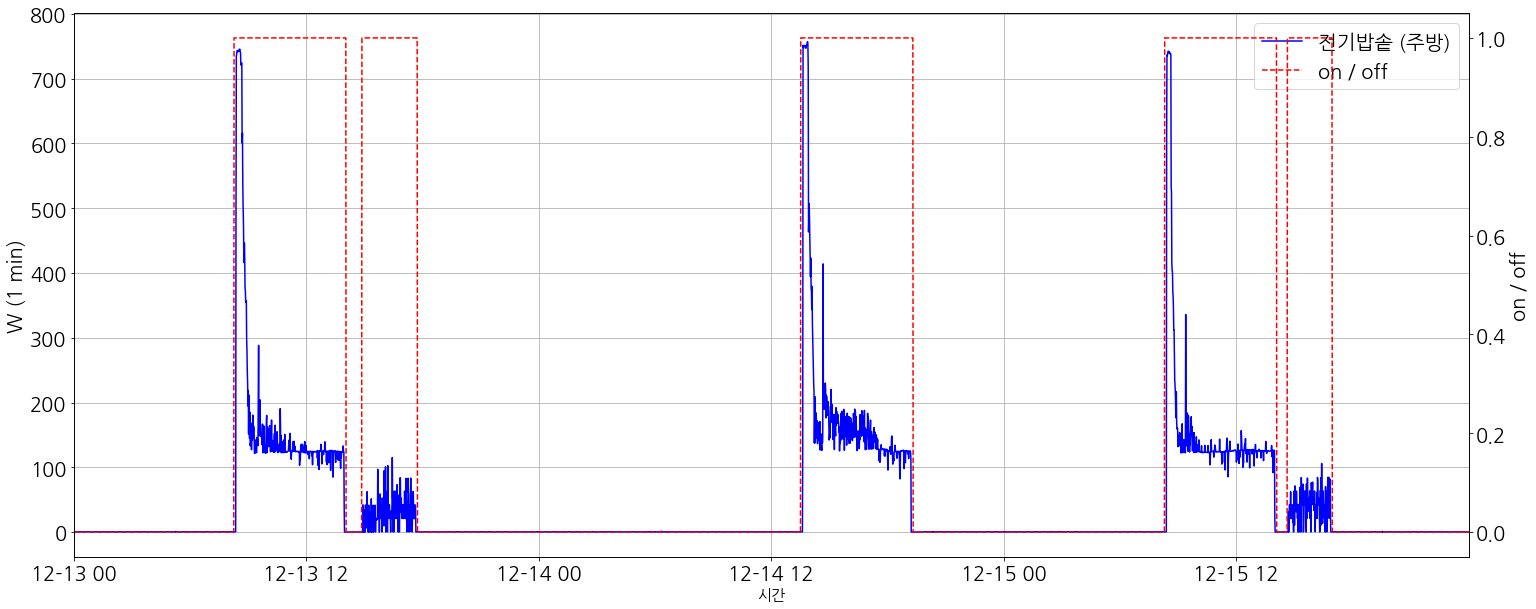
센서 데이터를 처리하는데 있어서 [Figure 1]에서 파랑 line으로 수집되고 있었다. 세탁기가 작동하는 구간에 대해 label = 1로 설정을 했지만, 단순히 측정된 Power (W)를 활용하여, threshold(e.g. 1~2)로 판단했을 때, labeling 결과가 나오지 못하고 있었다. (원인, 세탁기라는 가전제품의 특성으로 물이 들어오고 나가는 경우에는 전력소모가 없다는 점, Fail로 표기된 부분)

moving average, filter 등 여러 방법을 고민하던중. 결국 gaussian window (점선)을 이용하면 [Figure 2]와 같이 원하던 label을 할 수 있었으며, 이에 대한 원리 및 방법을 간단하게 살펴보고자 한다.

간단히 pandas df에서는 아래와 같이 mean() 또는 sum()에 대한 method를 사용할 수 있는데, 차이를 알아보자.
df.roliing().mean() / df.roliing().sum()
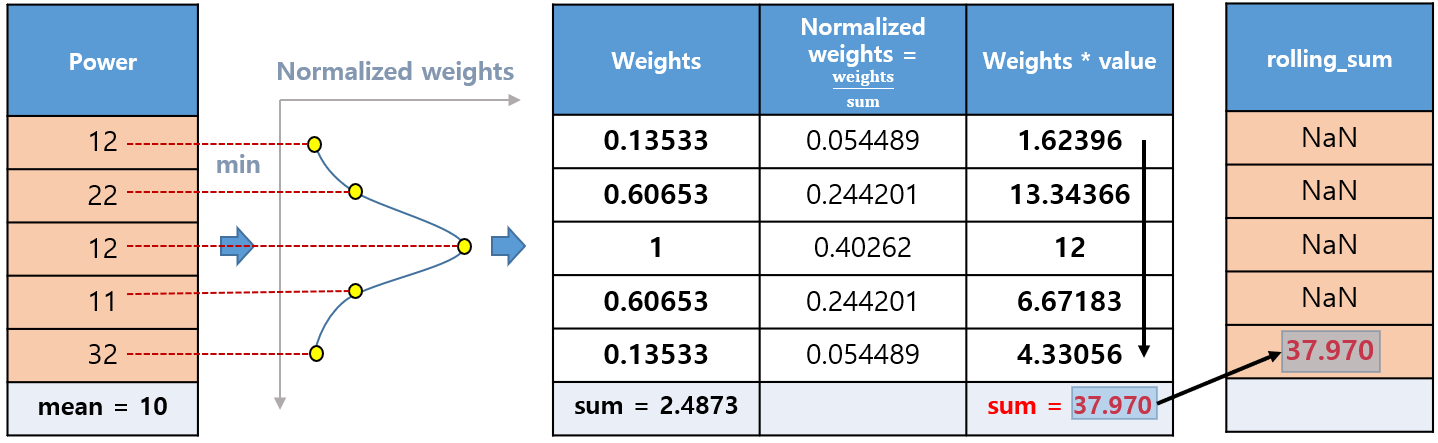
결론부터 말하면 측정된 value에 특정 gaussian distribution을 따르는 weights 및 normalized weights 를 곱하여 가중치가 적용된 value를 새롭게 얻을 수 있는 방법이다.
- df.rolling(window=5, center=False, win_type='gaussian').mean(std=1)
$\text{new_values}_{\text{mean}} = \text{values} \times \text{normalized_weights} \tag{1}\label{1} $

- df.rolling(window=5, center=False, win_type='gaussian').sum(std=1)
$\text{new_values}_{\text{mean}} = \text{values} \times \text{weights} \tag{2}\label{2}$

df.roliing(center=False).sum() / df.roliing(center=True).sum()
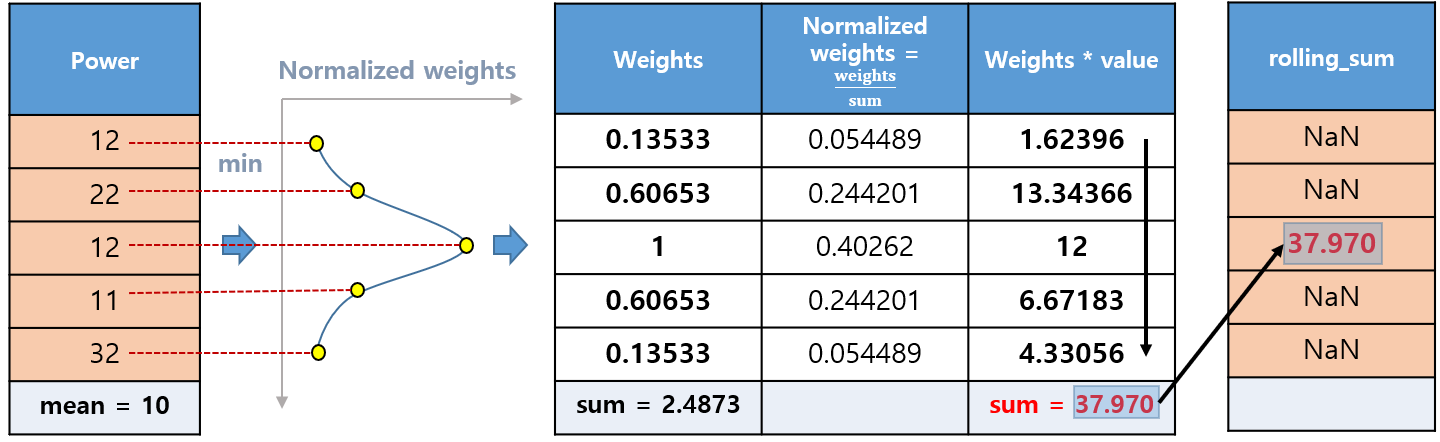
return 되는 index 위치가 아래와 같이 차이가 있다.
- df.rolling(window=5, center=False, win_type='gaussian').sum(std=1)
- df.rolling(window=5, center=True, win_type='gaussian').sum(std=1)
지금까지 gaussian weight를 활용하여 기존 값(value)를 weight가 적용된 새로운 값(new value)를 만드는 절차를 살펴봤다. 하지만, weight가 어떻게 얻어지는지 궁금하다면 Appendix를 참고하자.
Appendix : Gaussian distribution으로부터 weight가 얻어지는 절차
- $std = 1$로 가정
- 단, 아래의 $x$는 value가 아닌, point의 index의 즉, 위치를 나타내는 index

결론 및 느낀점
물론 위 방법 이외의 접근으로 labeling 작업을 할 수 있을텐데, 알고 있는 기법들 중에서 gaussian weight sum를 사용하는 것이 상대적으로 robust하게 labeling 할 수 있다는 point가 결정하게 된 계기다. labeling 작업뿐만아니라 실제 센서로부터 얻어지는 data의 noise가 있으므로, 이런 값들을 알맞게 대응하여 머신러닝/딥러닝 model의 input으로 사용한다면 더 좋은 성능을 얻을 수 있을것으로 판단된다.
- 다른 가전기기들도 수집되는 Power가 다양한데, 모두 이 기법을 활용하면 쉽게 labeling


댓글